<center>
# Vibe code isn't meant to be reviewed *
How to stay in control of codebase and not lose vibe code productivity boost
</center>
<img src="https://monadical.com/static/vibe-code-how-to-stay-in-control-robot-destroying-man-2.png"/>
> Disclaimer: The views and opinions expressed in this post are those of the author and do not necessarily reflect the official position of Monadical. Any content provided is for informational purposes only.
## The Code Review Frustration
Another day, another slop.
Chasing 10x productivity, you run several Claude code agents simultaneously and push code with blazing fast ferocity.
No juniors left on the team — they just couldn't catch up.
This morning, walking in the park with his dog, your team lead wrote and deployed a 100-story-point system just by casually talking on his phone to a remote agent.
Meanwhile, you're stuck with a code review:
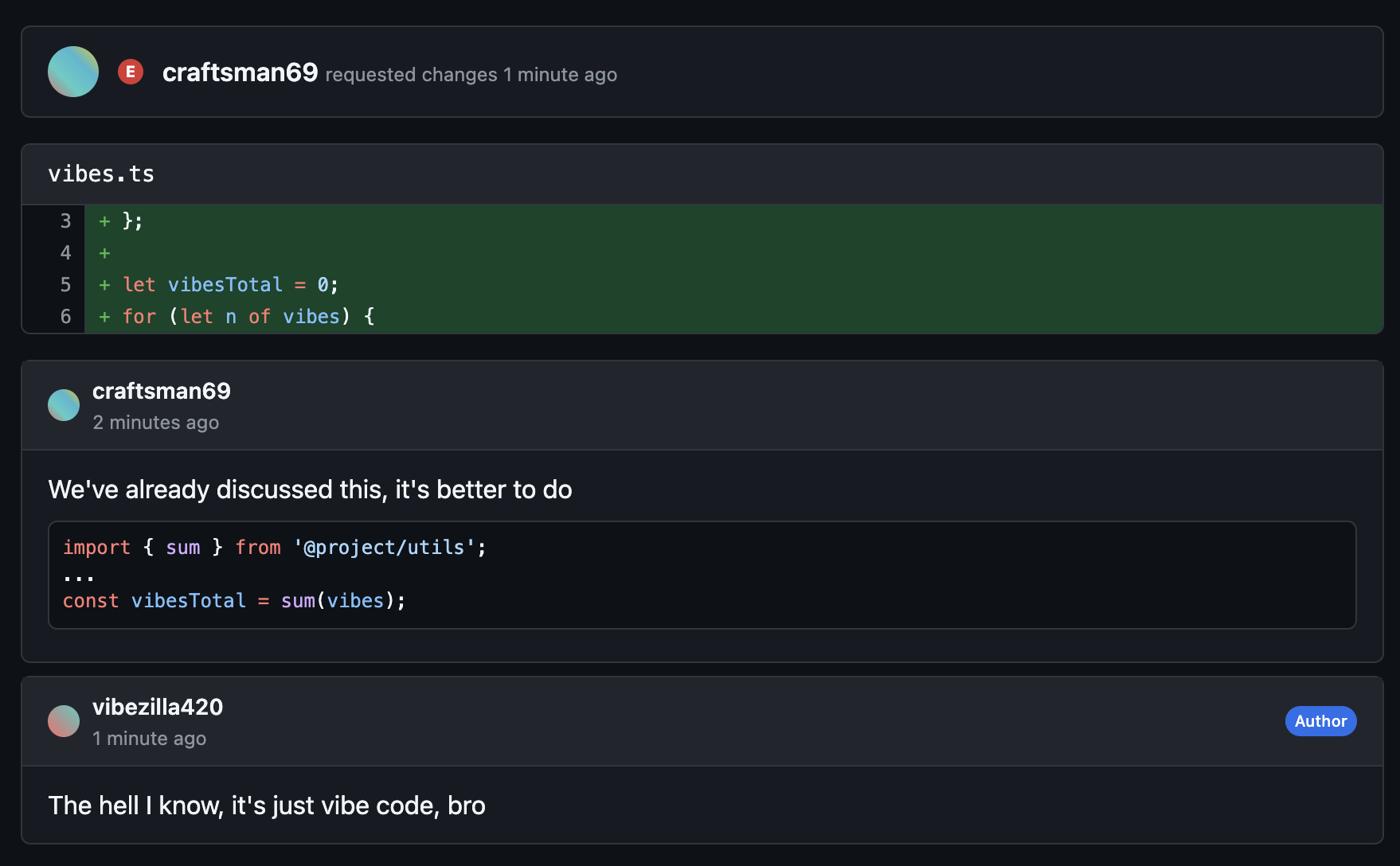
"It's fucking vibe code, I don't care!" — this sentiment is just the tip of the iceberg of a current industry problem:
<center><big>Treating all code the same when it fundamentally isn't</big></center>
## The Ownership Trap
Here's the brutal reality: **the moment you start treating AI-generated code as "precious," you lose AI's biggest superpower.**
Once you've spent time reviewing, fixing, and improving that generated code, you become invested. You're going to be extra careful about AI "breaking" it.
And it's ok, some code should be like this! But many times you just want to vibe and have your 10x productivity dream come true.
Treating vibe code as precious is the productivity killer nobody talks about. You get the initial speed boost, then gradually slide back to normal development velocity as your codebase fills up with "improved vibe code" that you're reluctant to throw away.
And you aren't ready to regenerate it from scratch anymore — an LLM skill that it excels at sometimes when it's stuck with a loop of never ending edits.
Meanwhile, every code review becomes a battle between two conflicting mental models:
- Reviewer: "This could be cleaner" (treating it like human code)
- Author: "It works, who cares" (treating it like disposable vibe code)
**The industry needs a way to keep these two types of code separate.**
## The Modular Solution: Giving Form to Chaos
The solution is neither to abandon AI coding nor to accept messy codebases. It's to **architect the separation explicitly.**
Think of it like this: Human code provides the "form" or "mold" that vibe code must fill. Just like the inpainting/outpainting feature in image generation. The human code contains your domain knowledge, business logic, and architectural decisions. The vibe code is just the implementation details that make it work.
When AI code is clearly separated and constrained by interfaces, tests, and clear boundaries, you can also regenerate it fearlessly while keeping your valuable insights intact.
### The Overseer Package Approach
#### The High-Level View
Before scaring managers and leads with implementation details, here's the conceptual framework:
1. **Interface packages** - Define contracts, data shapes, and the most important tests (human-written)
2. **Implementation packages** - Fulfill those constraints (Vibe-generated, marked as @vibe-coded in README or in files)
3. **Clear dependency direction** - Implementation depends on interfaces, never the reverse
4. **Regeneration freedom** - Any @vibe-coded package can be deleted and rewritten without fear
This creates a "constraint sandwich" - your domain knowledge stays protected while AI handles the tedious implementation work.
> Technical implementation example awaits you in one of the last paragraphs.
## Two Flavors of Review: Classic vs YOLO
With the modular approach and vibe code as "second class citizen," we can now reframe code review practices:
### **Classic review: High standards, educational, expertise-building**
Continue your nitpicky craftsmanship, talk about loops vs. combinators, and document your findings into project code style for LLMs to conform to.
Share knowledge, discover new details about the system.
### **YOLO review**:
"Does it work? Does it pass tests? **Doesn't it sneak around the overseer package requirements**? Does it look safe enough? Ship it."
<center><big>Clear separation of code "types" eliminates misunderstanding and friction</big></center>
## The Control Paradox Solved
There are deeper psychological and sociological nth-order benefits to this approach.
### Professional Confidence
When someone asks about a feature, you want to give an answer. "I don't know, I vibed it" destroys professional credibility. "Cursor can't find the answer today, try again tomorrow" makes you incompetent.
With explicit separation, you can confidently say: "The business logic is in the interface packages - here's exactly how it works. The implementation details are auto-generated, but the core logic is solid."
### Competitive Advantage
While others choose between "fast and messy" or "slow and clean," you get both. Your company's competitors using 100% vibe coding will hit complexity walls. Your company's competitors avoiding AI will be slower.
You'll maintain AI productivity gains while building systems that actually scale.
### Better "Boomer Business" Adoption
I believe that this approach could tip the scale for businesses who are still indecisive about vibe coding due to reliability and security concerns.
## Looking Forward: The Tooling Evolution
I strongly believe that in the near future, the distinction between vibe code and human code will be admitted by industry and integrated into existing tools.
### Git-Level Integration
Git commits automatically tagged as vibed. GitHub PRs showing clear visual distinction between human and AI contributions, up to the code line level.
### AI Agent Constraints
Future coding agents will have an option to respect "human code zones" - like content-aware inpainting for image generation, but for code. Agents could regenerate entire implementations, not only files or packages, but code line-wise, leaving human guidance code untouched.
### IDE Evolution
Syntax highlighting that dims unchecked vibe code while emphasizing human code. Folding options that hide implementation details. Search that prioritizes guidance, domain, architectural code.
### Corporate Adoption
This separation makes AI coding auditable and controllable - exactly what the bloody enterprise needs. CTOs can require that all business logic lives in human-controlled packages while allowing rapid development in implementation packages.
**So the idea of vibe code separation isn't just about individual productivity. It's about making AI coding enterprise-ready.**
## Technical Implementation in TypeScript
One of the ways to split vibe and human code using current tooling that I found is a per-package approach.
It's easy to do with a monorepo, but another structural or file-naming convention could work well too.
For the case of monorepo, I used the "-interface" packages that contain concentrated domain knowledge and shape-setting code (tests, interfaces).
I used dependency injection to draw more explicit frontiers between modules.
```ts
export type GenerateAndSyncTasksDeps = {
taskmaster: {
generateTasks: ReturnType<GenerateTasksF>;
};
tasktracker: {
syncTasks: ReturnType<SyncTasksF>;
};
};
export const generateAndSyncTasks =
(di: GenerateAndSyncTasksDeps) => async (prd: PrdText) => {
const tasks = await di.taskmaster.generateTasks(prd);
return await di.tasktracker.syncTasks(tasks.tasks);
};
```
This is the "entry point" of a module that receives a PRD document, uses https://github.com/eyaltoledano/claude-task-master to generate tasks, and then syncs them to a task tracker.
You can tell the coding agent to pick up from there, but it won't have enough guidance yet.
Therefore, "we need to go deeper." That's an example of how I defined the interface for taskmaster.generateTask, in its own package:
```ts
export type GenerateTasksDeps = {
savePrd: (path: NonEmptyString, prd: PrdText) => Promise<AsyncDisposable>;
cli: {
generate: (
prdPath: NonEmptyString,
tasksJsonPath: NonEmptyString
) => Promise<TasksFileContent>;
};
readTasksJson: (tasksJsonPath: NonEmptyString) => Promise<TasksFileContent>;
};
export type GenerateTasksF = (
deps: GenerateTasksDeps
) => (
prd: PrdText,
current: Option.Option<TasksFileContent>
) => Promise<TasksFileContent>;
export const generateTasks: GenerateTasksF = (deps) => async (prd, current) => {
if (Option.isSome(current)) {
throw new Error("panic! PRD update not implemented");
}
const prdPath = castNonEmptyString("scripts/prd.txt");
// not obvious: taskmaster CLI wants the prd first saved in file system
await using _letFileGo = await deps.savePrd(prdPath, prd);
const outputPath = castNonEmptyString("tasks/tasks.json");
await deps.cli.generate(prdPath, outputPath); // don't clean up here
// we read file system after CLI ran to return parsed tasks.json
return await deps.readTasksJson(outputPath);
};
```
Past this point, it's already possible to tell Claude Code to generate the `GenerateTasksDeps` providing code that calls the CLI, saves and reads from the file system.
Important details that we want to be preserved - "PRD file is temporary and we want to have it in the file system before calling CLI," "we also want to read the result of CLI call from the file system" are well-preserved as strong contextual harness for LLM code.
Data shape definitions are also a great candidate to use as controlling code:
```ts
export const TaskFileContent = Schema.Struct({
id: TaskId,
title: Schema.NonEmptyString,
description: Schema.String,
status: TaskStatus,
dependencies: Schema.Array(TaskId),
priority: Schema.optional(Schema.String),
details: Schema.String,
testStrategy: Schema.String,
subtasks: Schema.Array(SubtaskFileContent),
});
```
Interfaces too:
```ts
export interface TasksService {
list: (filters?: {
project?: ProjectId;
status?: StatusId;
user_story?: UserStoryId;
}) => Promise<readonly TaskDetail[]>;
create: (task: CreateTaskRequest) => Promise<TaskDetail>;
get: (id: TaskId) => Promise<TaskDetail>;
update: (id: TaskId, task: UpdateTaskRequest) => Promise<TaskDetail>;
delete: (id: TaskId) => Promise<void>;
}
```
And of course, unit tests are a great candidate for putting into controlling packages, especially [property-based tests](https://monadical.com/posts/property-based-testing-for-temporal-graph-storage.html).
Also, you can put there all the code that you *could* 100% vibe but better *don't* - that you're supposed to know, if not by heart, then at least "at some point when you wrote/reviewed it."
Tell the agent to conform to those interfaces, test and shape-setting functions, writing the "-implementation" package counterpart to your "-interface." An example system query: https://github.com/Monadical-SAS/taiga-taskmaster/blob/master/.llm-docs/PACKAGE_ORGANISATION_AND_CODE_SEPARATION_STANDARDS.md
To me, it worked handsomely. The agent was very strong at regenerating code anew if I didn't like something and wanted to add more context to the "control packages." And it never loses any context because of strict conformance to controlling code.
And for the PR process, it now becomes clear which code is worth more attention and which you can just glance over, which unlocks much more of vibe power without compromising quality.
