# To Fine-Tune or Not Fine-Tune: Large Language Models for AI-Driven Business Transformation
*Written by JDC and Hanna Jodrey. Originally published 2023-05-18 on the [Monadical blog.](https://monadical.com/blog.html)*
The buzz surrounding [**Large Language Models (LLMs)**](https://en.wikipedia.org/wiki/Large_language_model) is getting louder and more confusing by the day, but have no fear, we’re here to make it all make sense. We’ve been inundated with inquiries from leads, clients, and friends who are eager to learn about LLMs and their capabilities. To satisfy this growing curiosity, we’ve put together a comprehensive roadmap to the world of LLMs. We’ll give a brief overview of their origins, break down their training processes (with a focus on fine-tuning and prompt-based learning), and discuss safety considerations. We’ve also included practical examples of how LLMs can be deployed to enhance business operations, as well as a comprehensive discussion of current trends and future opportunities in both the community and the market. To avoid falling prey to misinformation or FOMO, keep reading for a deeper understanding of LLMs, how they can benefit your business, and the necessary steps to get started.
## LLMs - Large Language Models
So, what are LLMs? Simply put, they are a type of AI that can process human language and analyze text to extract useful information, which makes them excel at tasks such as language translation and generation, text summarization, question-answering, and [sentiment analysis](https://www.techtarget.com/searchbusinessanalytics/definition/opinion-mining-sentiment-mining). LLMs are made up of neural network models developed using [**deep learning**](https://en.wikipedia.org/wiki/Deep_learning) techniques that are trained on an incomprehensibly large quantity of information in order to recognize patterns and structures in language.
Specifically, engineers train an LLM by feeding it vast amounts of language data, like books, articles, and social media posts. The model then uses algorithms to learn language patterns such as sentence structure, grammar, semantics, and relationships between words and phrases. By ingesting this language data, the LLM can learn to understand and predict language inputs with increasing accuracy. Once trained, it can generate new text based on the patterns it has learned. As it becomes more proficient, it can generate original text that resembles human language, like responses to customer inquiries or social media posts.
Source: [Arxiv](https://arxiv.org/pdf/2108.07258.pdf)
The beauty of LLMs is that they can analyze vast amounts of structured and unstructured data, and then present the data in a relevant and applicable way. For example, if the goal is to facilitate information retrieval among a business’s employees, the business can develop a chatbot powered by an LLM that understands natural language queries and retrieves relevant documents, policies, or procedures. LLMs can also analyze customer feedback, reviews, and social media posts to extract insights into customer behaviour and preferences. Additionally, by automating mundane tasks like scheduling meetings, writing routine emails, or updating calendars, LLMs can free up employees' time for more valuable work. These are just a few of the many ways in which LLMs have the potential to revolutionize all areas of business.
## Where do LLMs come from?
LLMs have a long history rooted in the field of **[Natural Language Processing (NLP)](https://en.wikipedia.org/wiki/Natural_language_processing)**, which is an interdisciplinary subfield of AI, computer science, and linguistics, focused on the interactions between computers and human language. The first NLP program was introduced back in 1966 at MIT. This program, called ELIZA, was designed to simulate limited conversations with a human. Since then, NLP research has continued to advance, leading to the development of modern LLMs in 2017, when Google Brain introduced a groundbreaking paper called "[Attention Is All You Need](https://arxiv.org/abs/1706.03762).” This paper introduced the "**[Transformer](https://en.wikipedia.org/wiki/Transformer_(machine_learning_model))**," a novel neural network architecture that relied on "attention" and revolutionized the concept of LLMs. Unlike traditional networks, the Transformer was designed for sequence-to-sequence tasks, where both the input and output consist of sequences like sentences or documents. The introduction of the transformer architecture paved the way for the development of more advanced and expansive LLMs like [OpenAI's GPT-3](https://en.wikipedia.org/wiki/GPT-3), which served as the basis for ChatGPT and numerous other impressive AI-powered applications.
Consequently, the LLMs of today have become much more powerful, as they can now understand and create accurate responses quickly and effectively. For example, we asked ChatGPT to list the top three tourist destinations in Colombia; not only did it provide the destinations, but it also summarized their key highlights.

It’s notable just how far language models have evolved, considering their humble beginnings as a tool for completing sentences. What’s more, in recent years, platforms like [Hugging Face](https://huggingface.co/) and [BARD](https://bard.google.com/) have played a significant role in advancing LLMs by providing accessible frameworks and tools that empower researchers and developers to construct their own LLMs with relative ease. This level of sophistication is a testament to the remarkable progress made in the development of LLMs and their potential for transforming the way we interact with AI, and information in general. Let’s take a look at what makes this technology possible.
## How are LLMs trained?
**[Generative pretraining (GPT)](https://en.wikipedia.org/wiki/Generative_pre-trained_transformer)** is the first process used to train an LLM. It involves training the model on a vast amount of text data, allowing it to develop a general understanding of language patterns and relationships, without being tailored to a specific task. This approach first involves the [tokenization](https://en.wikipedia.org/wiki/Lexical_analysis#Tokenization) of the data (the process that converts a group of characters into meaningful chunks called text tokens, where each token represents a specific meaning or concept). After the model is fed with a large dataset of text tokens, it is able to learn how words and phrases are typically used together and the contexts in which they appear in a natural and unsupervised way.
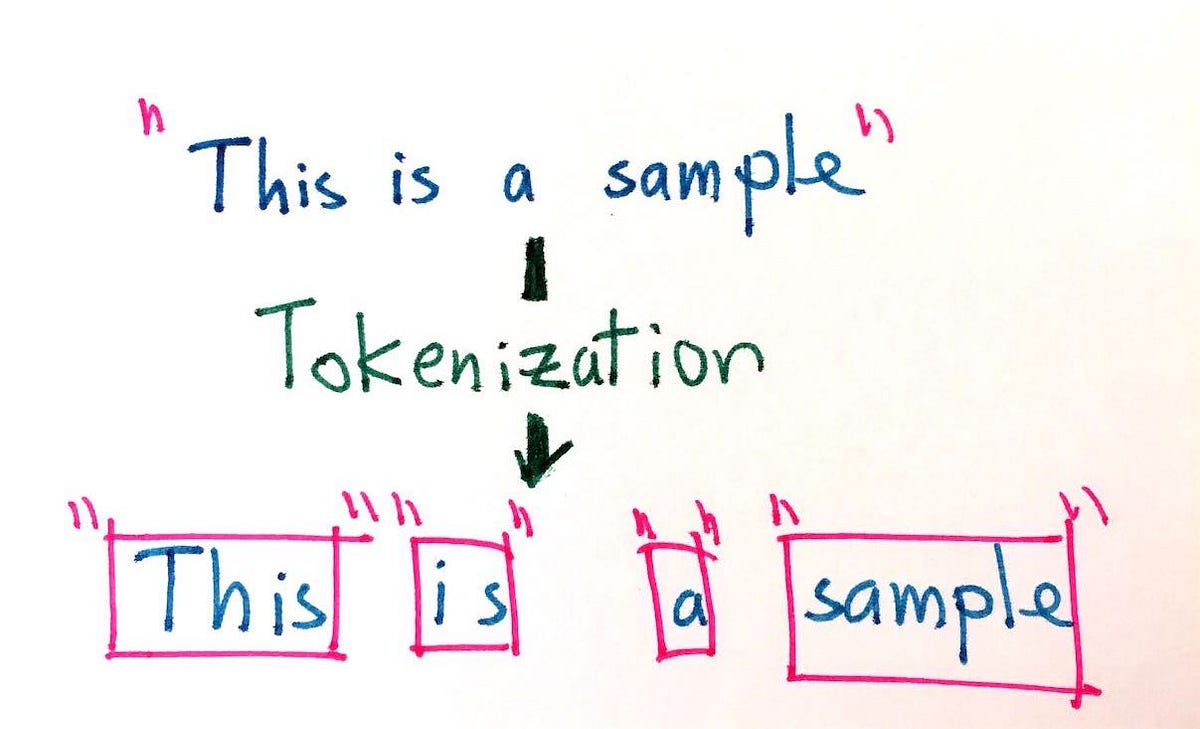
Source: [Medium](https://medium.com/data-science-in-your-pocket/tokenization-algorithms-in-natural-language-processing-nlp-1fceab8454af)
There are two main styles of generative pretraining used in LLMs: autoregressive and masked. The **autoregressive** model, or "GPT-style," invented by Google and picked up by OpenAI, is the model that is the most commonly used at the moment. Autoregressive models are designed to generate text by predicting the next word in a sequence given the previous text. Being pre-trained on a large amount of text data allows them to learn language patterns and relationships in an [unsupervised](https://en.wikipedia.org/wiki/Unsupervised_learning) manner. Autoregressive models can then be fine-tuned to be used for a specific task, such as language translation, text completion, or question answering, using a smaller, task-specific dataset.
**Masked models**, or "BERT-style," on the other hand, are a type of NLP model trained on a large amount of text data using masked language modelling (MLM). This involves randomly masking certain words in the input text, and then training the model to predict what those words are based on the surrounding context. By doing this, the model learns to generate more meaningful and coherent sentences. It can then be fine-tuned for specific NLP tasks, such as text classification, question answering, or sentiment analysis. Previously, masked models seemed to be better at **[Natural Language Understanding](https://en.wikipedia.org/wiki/Natural-language_understanding)** (NLU) tasks than the autoregressive models, but this no longer seems to be the case, as the autoregressive models are now coming to dominate the LLM scene.
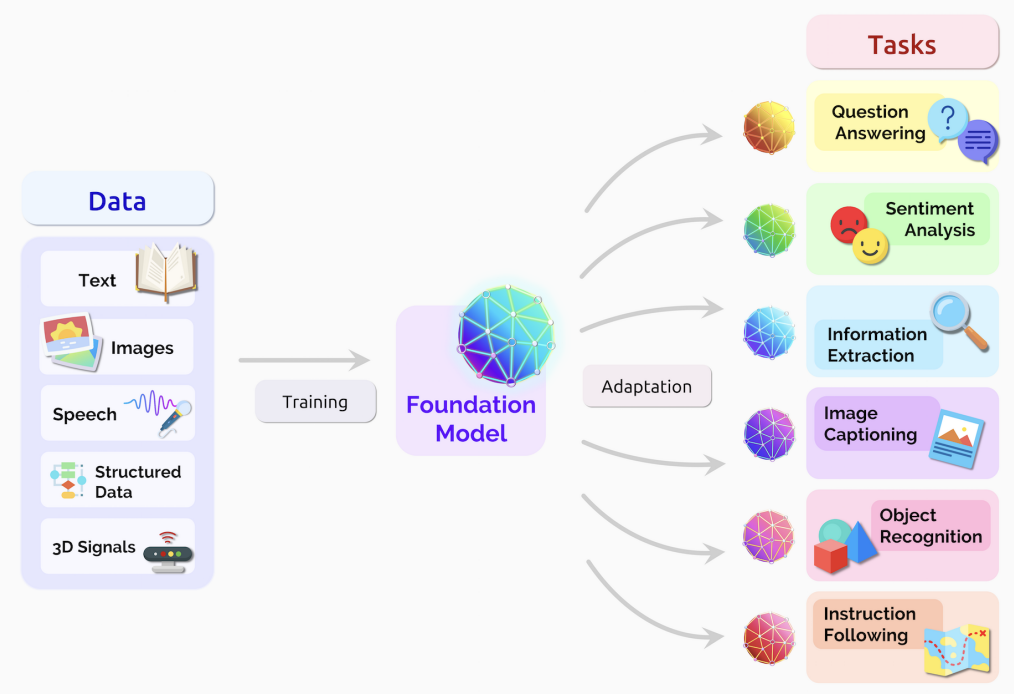
Once an LLM has been pretrained, it can be used as a [**foundation model (FM)**](https://snorkel.ai/foundation-models/) to build and fine-tune even more specialized models for a wide range of tasks. These foundation models can continue to learn new knowledge in two primary ways: by fine-tuning the model, or by inserting knowledge into the prompt. The approach used depends on the specific use case and the type of knowledge the model needs to learn.
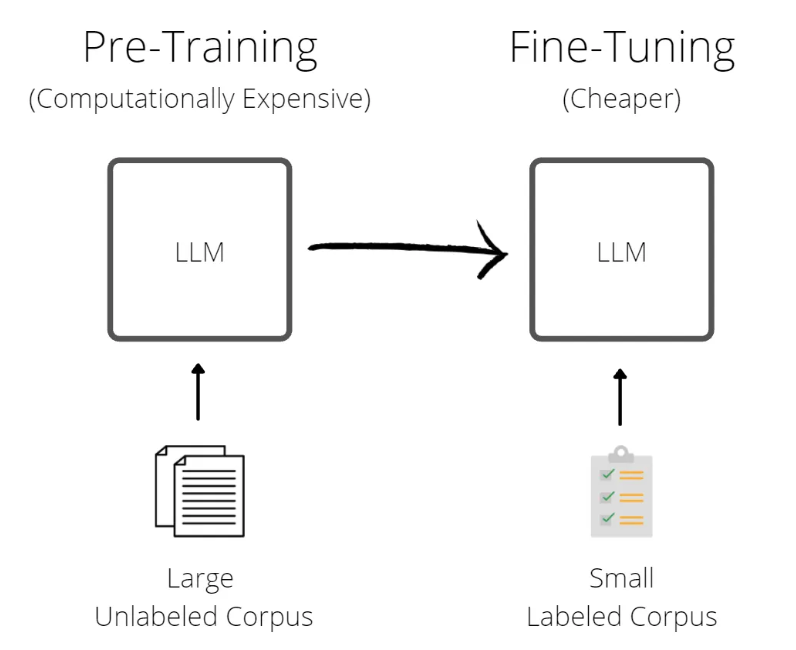
Source: [Medium](https://clive-gomes.medium.com/pre-training-large-language-models-at-scale-d2b133d5e219)
### Fine-tuning
Let's dive a bit deeper into how LLMs can be fine-tuned to improve their performance on specific tasks. [**Fine-tuning**](https://en.wikipedia.org/wiki/Fine-tuning_(machine_learning)) is basically giving the model some extra training on a smaller, task-specific dataset, which helps it better understand the nuances of the language and context it's dealing with. This can be extremely helpful in improving accuracy and reducing response times by using smaller models, which is crucial in many real-world applications.
For example, let's say a business wants to create a chatbot to handle customer inquiries on its website. By fine-tuning a pre-trained language model on a dataset of customer inquiries specific to their industry, the chatbot can be trained to better understand the language and intent of their customers, leading to more accurate and efficient responses.
Consider a real estate agency aiming to enhance customer service through a chatbot. By fine-tuning a pre-trained language model on a vast dataset of real estate customer inquiries, including property searches, pricing inquiries, and appointment bookings, the chatbot can gain a deeper understanding of industry-specific language and customer intents. As a result, when customers interact with the chatbot, it can provide more precise and prompt responses, offering property recommendations, answering pricing queries, and even scheduling property viewings.
However, it's worth noting that fine-tuning isn't always the best way to teach a model new knowledge. It can be computationally expensive, and the model may not always be reliable when it comes to factual recall. This is because the model weights, which determine how the model processes input data, can be compared to a human's long-term memory, which is prone to forgetting or even making things up.
That said, fine-tuning is still a wildly useful technique when it comes to adapting a pre-trained language model to a specific task or domain. By training it on a task-specific dataset, you can improve its performance and make it more suitable for the job at hand. This is especially helpful when dealing with specific industry verticals and the unique terminology that comes with them.
### Prompt-based learning
[**Prompt-based learning**](https://en.wikipedia.org/wiki/Prompt_engineering) is another powerful way for foundation LLMs to continue to incorporate new knowledge. The process involves providing specific prompts, or cues, to the model to generate more targeted and relevant responses. This can be particularly effective when dealing with specific topics or domains. In this approach, the prompt can be augmented with contextual data; for instance, it can include pairs of input prompts and target responses. During the response generation, the model uses the contextual information and stuffed instructions in the prompts to generate the responses. Prompt-based learning is highly efficient as the model can quickly generate new outputs without the need for extensive retraining or fine-tuning.

In the above example of prompt-based learning, the model sees a few examples of the task in addition to the task description.
Source: [The Gradient](https://thegradient.pub/prompting/)
[Prompt-based learning](https://prmpts.ai/blog/what-is-prompt-engineering) can be applied to diverse business contexts. Imagine a fictional company we’ll call TechGadgets; the company decides to leverage prompt-based engineering to create compelling marketing copy for their groundbreaking smartwatch "NovaTime." In order to do this, they fine-tune a language model using specific prompts to craft engaging content that showcases the sleek design, advanced features, and lifestyle benefits of the smartwatch. Through an iterative (back and forth) process, TechGadgets refines the prompts until they achieve persuasive copy that resonates with their target audience, effectively promoting NovaTime as a stylish, innovative, and personalized timekeeping companion.
### Emergent Abilities
In the world of LLMs, the performance of large models on different tasks could be inferred from scaling the performance of smaller models. However, there are instances where larger models experience a “discontinuous phase shift,” suddenly gaining unexpected abilities not found in smaller models. Researchers who have studied these [**emergent abilities**](https://openreview.net/forum?id=yzkSU5zdwD) extensively note that they cannot always be foreseen simply by extrapolating from the performance of smaller models. In fact, some of these abilities are only discovered after the LLM has been released to the public, when they appear in novel and unpredictable ways. Some of these newfound abilities include being able to figure out the intended meaning of a word, solve multi-step arithmetic problems, summarize passages of text, engage in [**chain-of-thought prompting**](https://learnprompting.org/docs/intermediate/chain_of_thought) (a new approach that enhances the reasoning capabilities of LLMs by adding intermediate reasoning steps), decode the International Phonetic Alphabet, pass college-level exams, and identify offensive content in Hinglish paragraphs.
## How can LLMs be used?
LLMs are certainly impressive when it comes to their apparent ability to understand and process language, yet it remains crucial to test their use cases and limitations. For businesses, using LLMs in the right way can lead to [massive improvements in efficiency and productivity](https://arxiv.org/pdf/2303.10130.pdf), ultimately resulting in big cost savings. By figuring out what tasks they're best suited for, and avoiding deploying them in situations where they won't add value, organizations can make better decisions about how to use these powerful tools. So it's important to weigh the pros and cons of LLMs, and figure out how they can be tailored to specific tasks.
### Natural Language Processing / Natural Language Understanding Tasks
Large, pretrained LLMs have achieved [impressive results](https://arxiv.org/pdf/2304.13712.pdf) in many Natural Language Processing (NLP) and Natural Language Understanding (NLU) tasks, but there are still some cases where smaller, fine-tuned models are more effective. The performance gap between fine-tuned models and LLMs can vary depending on the task and dataset, and each case should be evaluated individually. In cases where there is well-annotated data and few out-of-distribution examples (that is, data that is significantly different from what a model has learned), fine-tuned models tend to outperform large, pretrained LLMs.
Let's say you're a social media company looking to implement a model to detect toxic comments on your platform automatically. You have a large dataset of comments that have been labelled as toxic or non-toxic. In this case, you might want to consider using a fine-tuned model, as they have been shown to [outperform (simply pretrained and not fine-tuned) LLMs](https://arxiv.org/pdf/2304.13712.pdf) in toxicity detection tasks. Additionally, when it comes to traditional NLU tasks such as intent recognition (the process of understanding the user’s sentiment in the input and figuring out their objective), fine-tuned models are often preferred due to their strong performance on well-established benchmark datasets, and their lower computational cost.
However, large pretrained LLMs really shine when it comes to generalizing new and diverse data that falls outside of traditional NLP tasks. These large LLMs have been shown to outperform fine-tuned models on [out-of-distribution](https://ai.stackexchange.com/questions/25968/what-is-the-difference-between-out-of-distribution-detection-and-anomaly-detecti#:~:text=The%20term%20'out%2Dof%2D,from%20a%20'different%20distribution'.) and [sparsely annotated](https://ai.stackexchange.com/questions/34858/what-is-exactly-sparse-annotation#:~:text=in%20computer%20vision%20sparse%20annotations,zeros%20meaning%20no%20label%20given) data, which can be especially useful when dealing with messy real-world data that doesn't necessarily match up with training datasets. That's why it's important to carefully consider the task at hand and the available data before deciding which type of model to use for NLP/NLU applications.
### Natural Language Generation Tasks
[**Natural Language Generation (NLG)**](https://en.wikipedia.org/wiki/Natural_language_generation) is the AI-driven process that creates natural spoken or written language from [structured, semi-structured, and unstructured data](https://k21academy.com/microsoft-azure/dp-900/structured-data-vs-unstructured-data-vs-semi-structured-data/) and can be divided into two main types of tasks. The first type of NLG is all about taking an existing text and turning it into a new sequence of symbols. Examples include things like paragraph summarization and machine translation, where the aim is to create a shorter, more concise version of the original text. The second type of NLG is a bit more open-ended. Here, the aim is to create text or symbols completely from scratch, in a way that accurately matches an input description. Examples of this include writing emails, news articles or stories, and even generating code.
LLMs have shown to be incredibly powerful in [generating natural language](https://arxiv.org/abs/2304.02017), with the ability to generate cohesive, relevant, and contextually appropriate text sequences. These models have proven to be especially adept in [summarization tasks](https://www.forbes.com/sites/tjmccue/2023/01/26/chatgpt-hack-for-summarizing-your-work/?sh=6d61ee8c40a4), producing summaries that are not only high-quality but also highly fluent and coherent. In addition, LLMs have demonstrated impressive capabilities in open-ended generations such as writing news articles, stories, and even code synthesis. However, there are still certain use cases where LLMs may not be the best fit for NLG tasks. For example, in some [resource-rich](https://ieeexplore.ieee.org/document/9529190) translation tasks and certain extremely low-resource translation tasks (i.e. tasks where large data may not be available), fine-tuned models still perform better than simply pretrained LLMs.
### Knowledge-intensive tasks
Tasks in the field of NLP that need a lot of background knowledge, domain-specific expertise, or real-world know-how are called **knowledge-intensive NLP tasks**. These tasks are tricky to tackle using simple pattern recognition or syntax analysis. Instead, they require the use of memorized knowledge about specific entities, events, and the common sense of our world.
Pretrained LLMs have a huge advantage in knowledge-intensive NLP tasks because they possess massive real-world knowledge. They can memorize knowledge about specific concepts, ideas, and events, and utilize real-world common sense with ease. However, these LLMs can sometimes struggle, or even hallucinate, when the knowledge requirements don't match their learned knowledge or when they come across tasks that only require contextual knowledge. In such cases, fine-tuned models may outperform LLMs that are simply pretrained.
## Weighing the Risks and Benefits
When implementing LLMs in a business context, it's important to consider practical factors that directly impact a company’s operations and success, and efficiency, cost, and latency play crucial roles in optimizing the use of LLMs for maximum business value. To enhance efficiency, companies should prioritize maintaining up-to-date hardware and software systems that are specifically configured to handle LLMs coherently, ensuring smooth and swift processing. The cost factor is equally significant, as deploying LLMs can involve substantial expenses related to acquiring the necessary hardware infrastructure and managing computational resources for data processing. It is essential for businesses to carefully assess the return on investment and evaluate the long-term benefits against the associated costs. Moreover, in time-sensitive applications like chatbots or voice assistants, minimizing latency is vital. Businesses should focus on ensuring that their LLMs can generate quick and responsive outputs to deliver a seamless user experience.
While LLMs have shown impressive performance in various [downstream](https://www.baeldung.com/cs/downstream-tasks#:~:text=A%20downstream%20task%20is%20a,improve%20performance%20on%20specific%20tasks.) tasks, it's important to keep in mind other crucial factors when using these models, as LLMs also raise safety concerns that must be taken seriously. These concerns include privacy implications and the possibility of producing harmful or biased outputs, or hallucinations.
One of the major safety concerns of LLMs is the potential for them to generate [nonsensical or false information](https://arxiv.org/abs/2202.03629). These kinds of [**hallucinations**](https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)) can have serious repercussions on the reliability and quality of the model. This can be problematic if businesses rely solely on LLMs for decision-making or providing accurate information to customers, employees, or stakeholders.
[**LLMs can also pose a massive privacy concern.**](https://www.theregister.com/2023/03/15/gchq_warns_against_sensitive_corporate/) With these models, personal data can be disclosed without users knowing, putting sensitive information like PII (personal identifiable information such as names, social security numbers, biometric info, etc.) and other confidential data at risk. To mitigate these risks, it's crucial to use LLMs with care and establish strict guidelines for data handling and model deployment. As more data is fed into these models, the potential for privacy breaches only increases, making it even more important to be cautious.
In especially sensitive domains like healthcare, finance, and law, ensuring the reliability and trustworthiness of LLMs is of utmost importance. These fields demand the highest level of accuracy and accountability; yet, ensuring a model’s reliability and trustworthiness isn't always easy, since LLMs are incredibly complex and opaque.
[In healthcare](https://www.thelancet.com/journals/landig/article/PIIS2589-7500(23)00083-3/fulltext), LLMs are increasingly utilized for tasks such as medical diagnosis, patient monitoring, and treatment recommendations. For instance, an LLM trained on medical data can assist doctors in interpreting complex diagnostic images like MRIs or CT scans, aiding in the detection of abnormalities or potential diseases. However, the accuracy of LLM outputs must be ensured to prevent misdiagnosis or incorrect treatment decisions that could have severe consequences for patient well-being.
[In finance](https://www.forbes.com/sites/forbestechcouncil/2023/05/05/how-ai-and-llms-are-streamlining-financial-services/?sh=35fd0abf2301), LLMs play a vital role in fraud detection, risk assessment, and investment analysis. Specifically, LLMs can analyze vast amounts of financial data to identify patterns indicative of fraudulent activities or provide insights on investment strategies. Nevertheless, it is crucial to verify the accuracy and reliability of LLM outputs to avoid incorrect investment decisions, financial losses, or the misidentification of fraudulent transactions, which can undermine the integrity of financial systems.
Similarly, [in the legal field](https://arxiv.org/pdf/2303.09136.pdf), LLMs can be employed for tasks such as document analysis, contract review, and legal research. These models can efficiently process extensive legal texts, precedents, and case laws to provide valuable insights to lawyers and legal professionals. However, the integration of LLMs into the legal field has also introduced several legal problems, including privacy concerns and bias, among other concerns.
To address these concerns, there is a growing interest in developing [explainable AI systems](https://en.wikipedia.org/wiki/Explainable_artificial_intelligence). These systems aim to provide insights into the decision-making processes of LLMs, allowing humans to understand the reasoning behind their outputs. By incorporating explainable AI techniques into LLMs, [businesses can benefit](https://www.mckinsey.com/capabilities/quantumblack/our-insights/why-businesses-need-explainable-ai-and-how-to-deliver-it) from enhanced trust, accountability, and the overall reliability of the models. This fosters confidence in LLM outputs and facilitates the identification and mitigation of potential biases, errors, or ethical concerns that may arise.
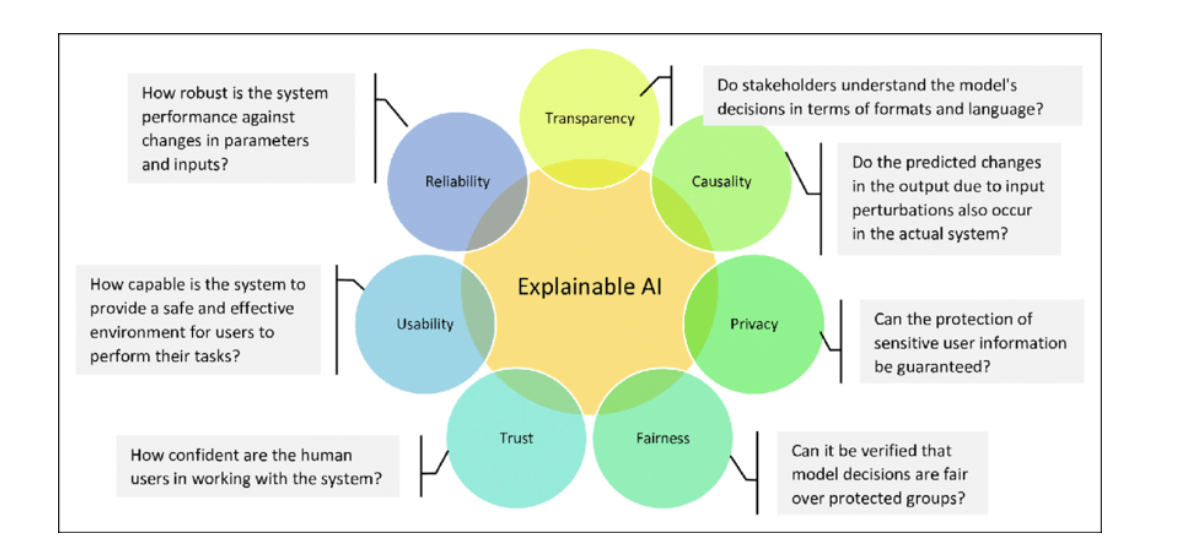
Goals of Explainable AI
Source: [ResearchGate](https://www.researchgate.net/figure/Goals-of-explainable-AI-XAI_fig1_353200175)
Ultimately, the responsible use of LLMs with transparent decision-making processes is essential to ensure their effectiveness and trustworthiness in critical domains.
## Current Trends
Even with the rapidly changing environment, and despite the safety considerations, businesses are still keenly aware of the promise and potential LLMs offer, and developers are building new tools and applications every day. Let’s take a look at some of the most current trends that are relevant for those looking to build in this space.
### Community-based initiatives
[**AutoGPT**](https://github.com/Significant-Gravitas/Auto-GPT), [**babyagi**](https://github.com/yoheinakajima/babyagi), and [**OpenAssistant**](https://github.com/LAION-AI/Open-Assistant) are three exciting chat-based projects on Github that have the potential to redefine how businesses operate. These models are capable of understanding tasks, interacting with third-party systems in some cases, and dynamically retrieving information to execute tasks in order of priority. With these LLMs, businesses can increase efficiency and productivity, and save time and resources by automating repetitive tasks like writing routine emails or updating calendars. Companies can also save time by using these tools to generate content such as social media updates or blog posts, or by providing customer support in the form of an LLM-powered chatbot.
**Open Source Models:** Among developers and businesses alike, there is a growing push towards [open-source](https://en.wikipedia.org/wiki/Open_source) large language models. The use of open-source models promotes transparency and allows more people to access powerful AI tools, democratizing access to this technology. As this trend continues to gain momentum, we expect that open-source models will soon catch up to proprietary models like OpenAI. Currently, [Vicuna13B](https://lmsys.org/blog/2023-03-30-vicuna/) stands out as the most capable open-source model for general tasks, but we're confident that more high-performing open-source models will become available soon. By embracing open-source models, businesses can benefit from increased access to powerful AI tools, promoting innovation and driving progress in the industry.
The **BYOM (Bring Your Own Model)** approach enables businesses to switch between LLMs based on the specific task, to benefit from the specific strengths of different models. For instance, businesses can use LLMs trained on private data for tasks like writing emails without compromising their security, while using OpenAI's model for more general chat. [**Window AI**](https://windowai.io/) is a great example of a platform that supports BYOM by providing a browser extension that allows users to switch models easily. In the future, expect to see a wide variety of LLMs optimized for specific services like email writing, customer service, and more. The BYOM approach enables businesses to unlock the full potential of LLMs, optimize their workflows, and increase efficiency.
[**Software development kits (SDKs)**](https://en.wikipedia.org/wiki/Software_development_kit) and connectors play a crucial role in integrating LLMs and agents for various business applications. [**LangChain**](https://github.com/hwchase17/langchain) and [**LlamaIndex**](https://github.com/jerryjliu/llama_index) are two examples of projects that create software patterns for running LLMs, indexing and retrieving data, and automating agent-related tasks. This includes facilitating prompt execution, supporting interfaces for multiple language models and pipelines for consolidating results, accessing external data sources through APIs, segmenting documents, and feeding them to vector databases for context augmentation such as RAG. These SDKs and connectors help businesses optimize their workflows, enhance productivity, and improve decision-making capabilities by leveraging the power of LLMs.
**Vector databases** play an essential role in storing and indexing text-based data and augmenting the context of several tasks. These databases act like a memory, allowing businesses to retrieve the most relevant pieces of content. There are numerous options available, including open-source databases like [**Milvus**](https://github.com/milvus-io/milvus), [**Weaviate**](https://github.com/weaviate/weaviate), [**Qdrant**](https://github.com/qdrant/qdrant), and LlamaIndex. By utilizing vector databases, businesses can easily search through vast amounts of data, find relevant information quickly, and gain insights that can help them make informed decisions. For example, vector databases can assist businesses with talent acquisition by storing candidate profiles and job requirements as vectors. Then, by searching through these databases, businesses can match applicants’ skills and qualifications with job requirements, and quickly find suitable candidates.
### In the market
Let’s check out some of the most important trends happening among some of the major players in the market.
[**AWS Bedrock**](https://aws.amazon.com/bedrock/) is a platform designed to provide businesses with easy access to foundational language models from the top AI companies, including Cohere, AI21 Labs, Anthropic, and Stability AI. These models can be fine-tuned for specific business needs using powerful computational resources and specialized software chips that are specifically designed for NLP tasks. AWS Bedrock aims to assist businesses build high-quality, accurate, and scalable NLP applications quickly and easily, without worrying about the underlying infrastructure.
[**OpenAI**](https://openai.com/) has recently introduced plugins that can enable businesses to access external resources and create versatile and relevant applications. These plugins can be utilized to perform tasks such as making travel reservations or booking restaurants. Developing plugins is relatively straightforward, and businesses can provide a summary and description of the plugin's actions to select the appropriate model and collect the necessary information. Additionally, OpenAI is working on making its most complex language models accessible via APIs, allowing resource-intensive tasks to be offloaded to the cloud. By utilizing OpenAI plugins and APIs, businesses can leverage powerful language models to streamline their workflows and improve their services.
[**Neural Search**](https://jina.ai/news/what-is-neural-search-and-learn-to-build-a-neural-search-engine/): there is a growing trend of using LLMs for search applications. These models offer a more advanced search experience beyond traditional keyword-based approaches, thanks to their ability to utilize semantic search and other techniques. This allows LLMs to interpret and understand the meaning behind users' queries, resulting in highly accurate and relevant search results. As such, many companies are investing in the potential of LLMs to improve their search capabilities, paving the way for an era of intelligent and personalized search experiences.
Finally, [**Cohere**](https://cohere.com/), [**AI21 Labs**](https://www.ai21.com/), [**Anthropic**](https://www.anthropic.com/), and [**Stability AI**](https://stability.ai/) are all companies that are included in the AWS Bedrock platform. Unlike OpenAI, these companies are likely to monetize their models by offering access to foundational models for rent. This can provide businesses with the opportunity to leverage advanced language models for their specific needs and potentially improve the accuracy and relevance of their services.
## Opportunities
Since the technology and associated business-driven applications of LLMs are currently speeding along at a dizzying pace, it can be difficult to predict just where we’ll end up. However, we can still explore current and future opportunities, based on the trends explored in the previous section.
### Fine-Tuning Models for Specialized Tasks
Companies that require specialized tasks (such as machine repair instructions, self-troubleshooting, diagnostics, etc.) or that have unique datasets can benefit from fine-tuning language models. As we’ve already discussed, fine-tuning enables organizations to create models that are tailored to their specific requirements and data sets, resulting in improved accuracy and efficiency. The benefits of deploying a custom model can be significant, including reduced operational costs, improved customer experience, and increased productivity.
### Creating Systems for Niche Use Cases
Creating heuristics and systems for niche use cases that are not tackled in the training sets of big models yet is another area where LLMs can provide business value. For example, chat conversations can generate valuable insights that can be used to provide event suggestions, participant recommendations, document suggestions, and more. Leveraging the power behind the models ensures that organizations can create customized systems that deliver highly personalized experiences to both clients and employees.
### Improving Chatbots, Recommendation Systems, and Data Products
LLMs are also being used to improve chatbots, recommendation systems, and data products. By integrating the models into these systems, companies can enhance their functionality, resulting in more accurate and relevant recommendations, better customer support, and improved data analysis. Language models can also be used to generate more natural and engaging conversations with customers, leading to increased engagement and loyalty.

A strikingly prescient cartoon by H.T. Webster from 1923
Source: [Ars Technica](https://arstechnica.com/information-technology/2023/01/a-cartoonist-predicted-2023s-ai-drawing-machines-in-1923/)
At Monadical, we are excited about LLMs and their potential to revolutionize the way businesses operate. This technology will undoubtedly assist companies in gaining a competitive edge and will drive growth. As we've explored in this article, LLMs are already being used by businesses in a variety of industries and offer many benefits. As the tech continues to evolve, we can expect to see even more innovative use cases emerge.
We believe that LLMs are an exciting and valuable technology that can help businesses unlock new insights and deliver better customer experiences. We love talking and learning about LLMs and everything they offer, so don’t hesitate to comment or message us if you want to chat!
## References
https://arxiv.org/abs/2304.00612
https://arxiv.org/abs/2203.02155
https://arxiv.org/abs/2304.10513
https://arxiv.org/abs/2304.13712
https://arxiv.org/abs/2304.15004
https://arxiv.org/abs/2303.12712
https://arxiv.org/abs/2303.08774
https://arxiv.org/abs/2304.13712

JDC
is a Partner of Monadical
