<center>
# Event-Driven Architecture
<big>
Lessons Learned in Building a Poker Platform with Event Sourcing
</big>
</center>
<br/>
<i> <small>Written by Max McCrea. Originally published 2020-12-24 on the [Monadical blog](https://monadical.com/blog.html).</i></small>
### Introduction
> <i> <small> The experience of seeing a log dump next to a bug report, pointing a new test case at the log, calling a single function to reproduce the exact state of the world at the time of the error, and being able to introspect everything, as well as step forwards and backwards through time, is special. </small> </i>
When Nick and I started working on OddSlingers in 2016, we wanted to build something cutting-edge, and had been recently influenced by some of the functional programming advocates we’d become friends with at the [Recurse Center](http://www.recurse.com/).
We’d also read Jay Kreps’ wonderful article, [The Log: What every software engineer should know about real-time data’s unifying abstraction](https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying), and learned to [turn the database inside out](https://www.confluent.io/blog/turning-the-database-inside-out-with-apache-samza/) from Martin Kleppman. We had witnessed the rise of [Redux](https://redux.js.org/) as React’s state-management saviour, and couldn’t wait for the gods of code to hand us our DeLoreans for [time-travel debugging](https://medium.com/the-web-tub/time-travel-in-react-redux-apps-using-the-redux-devtools-5e94eba5e7c0). And let’s not forget the blockchain[^blockchain]!
[^blockchain]: Bitcoin’s success is a result of its clever combination of the ideas of [proof of work](https://en.wikipedia.org/wiki/Proof_of_work), [merkle trees](https://en.wikipedia.org/wiki/Merkle_tree), and event-driven architecture. An (oversimplified) explanation of the latter: each `block` in the `blockchain` is effectively a list of `transactions`, or updates to the `ledger`. For example, a `transaction` might be “I sent one unit of cryptocurrency from my `address` to John’s”. Finding the current balances of all addresses is a matter of running a [fold](https://en.wikipedia.org/wiki/Fold_(higher-order_function)) (aka reduce, aggregate, or accumulate, depending on your language of choice) function over the whole chain. These `transactions` are conceptually equivalent to `events`.
Seeing the benefits of this approach, we set out to build our game platform using an event-driven architecture (also known as log-structured or [event sourcing](https://martinfowler.com/eaaDev/EventSourcing.html)). But that doesn’t mean we got to work installing Kafka and Samza; you don’t need any heavy frameworks or tools to reap the benefits of event-driven architecture. In fact, we ended up storing our Django models and event logs in the same postgres database!
It just means we built our codebase around the idea that we should have a single event stream, that we should store it in a log, and that all application states should be reproducible given a starting state and that log.
Once we got some reasonable abstractions figured out, having an event-driven architecture was a thing of beauty. The experience of seeing a log dump next to a bug report, pointing a new test case at the log, calling a single function to reproduce the exact state of the world at the time of the error, and being able to introspect everything, as well as step forwards and backwards through time, is special. For gnarly, complicated code full of interdependent state transitions and edge cases (like, say, game logic), it can feel almost blissful.
But there were downsides to this decision too, and I hope our journey will show both the benefits and drawbacks of event sourcing.
### Event-Driven Architecture
Let’s start with a very quick explanation of what event-driven architecture is.
It’s an architecture based on one core idea: any given state can be defined as a starting state and a series of changes applied to that starting state in succession. We call such a change an “event,” and given a starting point and a log of events, you can always reproduce any state at any time in history.
For example, let’s imagine (in some hypothetical world) that you are building a poker platform. You might start with a database with a [schema](https://en.wikipedia.org/wiki/Database_schema), things like `User`, `Player`, `PokerTable`, etc. And that database would start out empty. Then some people sign up. They sit at a table, and play some hands of poker.
In a typical architecture, each of those actions (people sign up, sit at a table, play some hands) are defined by a series of requests over some protocol (e.g. HTTP), and each results in the modification of the database state (e.g. the addition of a row in the `User` table). The event-driven approach sees the series of changes to the database as the fundamental source of truth. This means that, given a snapshot of a database in some state, we can produce all future states.
<center>
<img style="width:400px" src="https://docs.monadical.com/uploads/upload_e1817015693a41a4dacde4e069a75f5d.png" alt="State change in event-driven architecture"/>
<small><i> A starting state, log, and current state. <br/> State change in event-driven architecture is linear and deterministic! If there was a bug that happened when the second player sat, we can fire up a test database, point our codebase at it, and dispatch the first two events to reproduce it. </i></small>
</center>
Here’s a simplified version of what our architecture ended up looking like[^detailed]:
[^detailed]: If you’re curious to learn about the architecture in all its glorious detail, I recommend [starting here](https://github.com/Monadical-SAS/oddslingers.poker/wiki/Layers-of-the-Stack).
<center>
<img style="width:400px" src="https://docs.monadical.com/uploads/upload_b5e363ae7cf10a27975aac57cb4e3b75.png" alt="OddSlingers heirarchical architecture"/>
<small><i>A hierarchical, linear architecture is easy to follow! The “controller process” is where the magic happens, and I’ll be going into much more detail about how that works in the next section.</i></small>
</center>
There are some notable advantages to this approach:
* If the state of my database ends up broken somehow (e.g. because of a logical error), I can go back in time and figure out how it got that way.
* If I want to add another kind of data store, I can keep their states consistent by keeping both dependent on the same event history.
* Creating a realistic simulation of production conditions for testing or research purposes becomes just a matter of pouring an actual historical log into a test database or service.
* It creates a clear hierarchical flow of state dependency, which massively reduces the number of things developers have to reason about in any one part of the codebase.
There’s a lot of overlap with ideas from [functional programming](https://en.wikipedia.org/wiki/Functional_programming), and our ideas were influenced by [Rich Hickey](https://www.infoq.com/presentations/Simple-Made-Easy/) and [Gary Bernhardt](https://www.destroyallsoftware.com/talks/boundaries). Indeed, taking as much advantage as possible of pure functions, while isolating side effects (e.g. in our use of `Subscribers`), was a core goal of our design.
### Models, Events, Dispatch
Armed with the “why,” let’s take a look at how our backend, which was built with the [Django](https://www.djangoproject.com/) framework, applied the principles of event-driven architecture. We chose Django because it’s a robust, battle-tested web framework, and because it manages to have nice ergonomics without excessively leaning on metaprogramming magic[^django]. Also, its migration system is a really nice feature for the long-term health of a project.
[^django]: Looking back, there were two problems with using Django: one was that it wasn’t designed to be used with websockets, and so we had to build a way to handle push/pull. Luckily, Andrew Godwin was simultaneously working on [django channels](https://github.com/django/channels), which we replaced our (similar) solution with early on. The second problem is that it’s a bit slow for a game engine, and it’s hard to spend less than 50ms just in Django processing a request. That mostly isn’t a problem in poker (a turn-based game), but it made it hard, for example, to get a checkbox to feel snappy when it had to make a round-trip to the server.
<center>
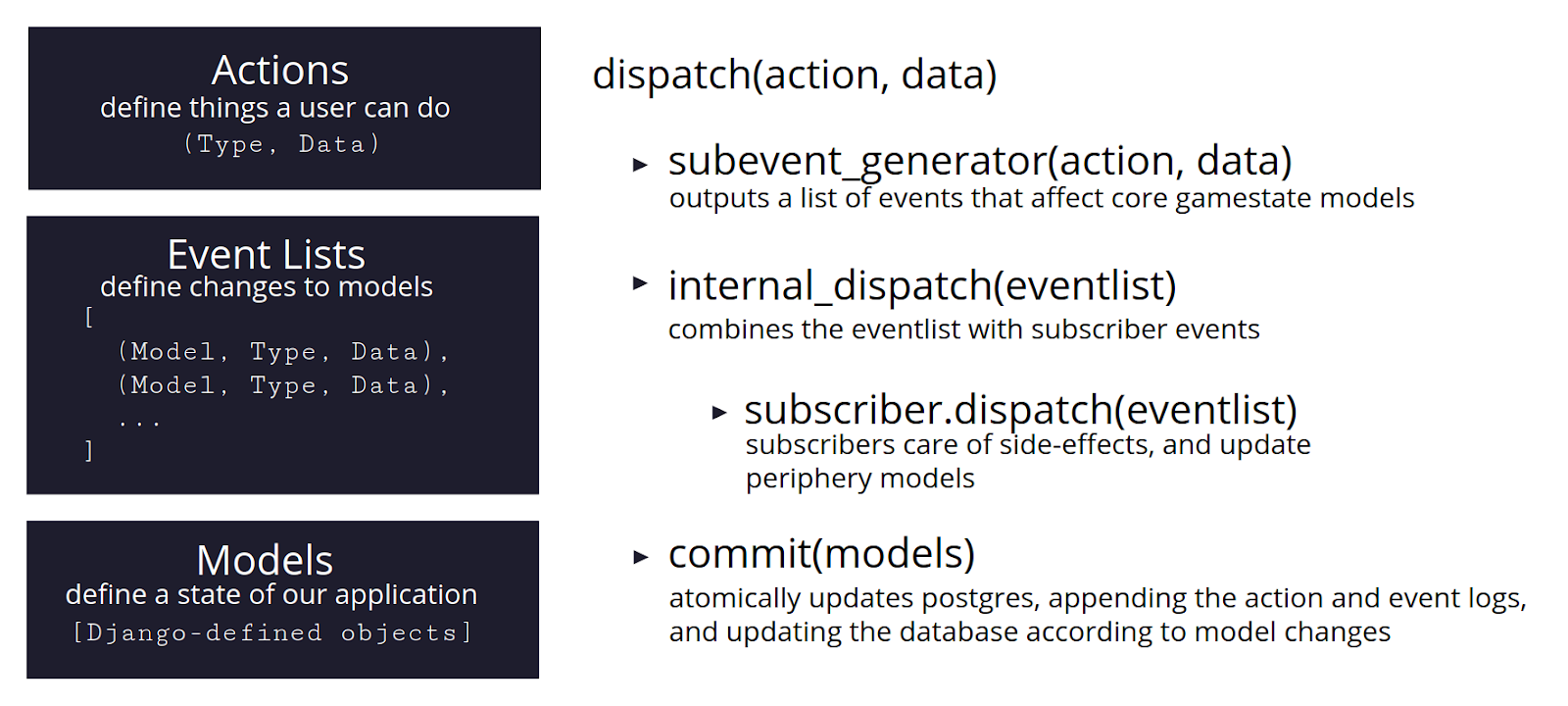
<small><i>The `Controller`’s `dispatch()` cycle determines how a given `Action` modifies application state, and then `commit()`s that action and its state changes to the database. </i></small>
</center>
In a typical Django project, getting `Models` (which define a database schema for Django’s ORM) right is a good first step. The `Model` objects will represent an in-memory, pythonified cache of the state in our database. We also defined a set of `Events`, which would effectively be the model layer’s API, which would eventually be overshadowed by `Actions` (mirroring `redux` again), which effectively defined the application’s API.
Once some `Models` are defined (`Player`, `PokerTable`[^tip], `Deck`, …), we need a way for incoming http requests to result in changes to them. So incoming requests, after hitting nginx and getting queued via Django-channels, are picked up by a worker process[^scaling], and passed into a `Controller`, which handles all business (or game, in this case) logic.
[^tip]: Pro-tip: never name a database table `Table`.
[^scaling]: We chose to use exactly one process per poker table, which made horizontal scaling very easy, and avoided most concurrency questions. And the event-driven architecture allowed us to, for example, kill all processes and start them up again on new machines, where they would read the logs and get their states back to where they were supposed to be.
The entrypoint into the `Controller` is the `dispatch()` function (so named to follow `redux`; more on our frontend in part 2). It passes the incoming data around through a series of functions that come up with a list of modifications to make to the in-memory `Models`.
It then passes those `Events` to the `internal_dispatch()`, which handles `Subscribers` and applies the changes to `Models`. `Subscribers` handle side effects (for example, computing an animation to send to the frontend) and can produce `Events` of their own, to be grouped up with those produced earlier by the `subevent_generator`. Finally, all of those `Events` are processed: each one applies its designated change to its designated `Model`.
When they’ve all been updated, a single `commit()` is executed. By batching all the writes until the end of the event lifecycle, we could make sure that all of the data changes would occur atomically without needing to lock for excessive amounts of time.
Note that we called the low-level changes to the database `Events`, and later added a higher-level layer called `Actions` (to mirror [Redux Actions](https://redux.js.org/tutorials/fundamentals/part-2-concepts-data-flow#actions); I’ll go more into that in part two). The `Action`/`Event` dichotomy isn’t totally necessary[^benefits], and it’s there in part because we didn’t quite get the level of abstraction right[^DDD] when we designed our events in the first place. After defining `Events` in terms of logical units of change to `Models`, we found a level of abstraction that sat atop it (equivalent to an API) was easier to work with. We didn’t want to change existing `Events`, because it would involve overhauling the whole codebase. I believe that this is the one real downside of event-driven architecture: changing your event model down the road is very tricky!
[^benefits]: The `Action`/`Event` dichotomy has its benefits. For example, every level of our hierarchy has its own `dispatch()`, right down to the models, which means devs always know where to look to understand how a state was reached. But it’s also a bit confusing to have both, and the historical log of `Events` is maddeningly long. It also wasn’t often useful for debugging, in practice, because API-layer history is easy to reason about, whereas `Model`-layer history is incredibly long and noisy, making it difficult to parse for a human being. Besides, you can always just step through a dispatch cycle in ipdb and diff two states to get information at the same level of granularity.
[^DDD]: The `Action` abstraction ended up essentially being the vocabulary of the game of poker, and was a big improvement over the original `Event`s, which mixed things like `RAISE` and `FOLD` with lower-level concepts like `POP_CARDS` and `RETURN_CHIPS`. The experience convinced me of the importance of [domain-driven design](https://en.wikipedia.org/wiki/Domain-driven_design)!
### Walking Through an Example
Let’s walk through what happens when a player goes all-in[^poker], to illustrate what this looks like in practice. And just to note: this is a simplification of how our code actually works, because it would be unwieldy to have to explain every abstraction we use in our codebase[^code].
[^code]: Learn about how our actual code works, in all its gritty detail, by checking out [our docs](https://github.com/Monadical-SAS/oddslingers.poker/wiki/Game-Engine).
At this point, we’re assuming that a request has been passed through the websocket handlers and popped off the process queue, and is about to be passed into the `dispatch()` function of the `Controller`:
[^poker]: “All-in” means to put all of your chips into the pot. For an explanation of the basic mechanics of poker, you can check out the [OddSlingers learn page](https://oddslingers.com/learn/).
```python
controller.dipatch(
'RAISE_TO',
amt=100,
all_in=True,
player_id=example_player.id,
)
```
```python
# simplified excerpt from file controllers.py
class GameController:
# ...
def dispatch(self, action_name: str, **kwargs) -> None:
subevent_generator = getattr(self, action_name.lower(), None)
events = subevent_generator(**kwargs)
self.log.write_action(action_name, **kwargs)
self.internal_dispatch(events)
self.commit(should_broadcast=action_name in PUBLIC_ACTIONS)
```
There are a few steps here:
* The `subevent_generator`, in this case, is the function `raise_to` on the controller, which will return a list of (`subj`, `event`, `kwargs`) tuples, which will define the list of changes that will be made to the gamestate.
* `subj` is a database model (such as a `Player` object).
* `event` is an `Enum` such as `Event.UPDATE_STACK`.
* `kwargs` are whatever that event needs to resolve, such as `{'amt'=0}`.
* Next, the action is added to the historical log, which will make it possible to do things like time-travel debugging later on. We ended up using the same structure as a subscriber for the log, and it, like the other subscribers, writes to the same postgres database as everything else. A log might look like this:
```python
"actions": [
{
"subj": "cowpig",
"action": "RAISE_TO",
"args": {"amt": 100}
},
{
"subj": "pirate",
"action": "FOLD",
"args": {}
},
# … many more actions
]
```
* Then the `EventList` is passed into `internal_dispatch`, which makes the changes to the relevant models, and also passes the `EventList` to any subscribers[^subs] that are listening (for example the `NotificationSubscriber`, which decides when to send notifications). That function essentially looks like this:
[^subs]: The `BankingSubscriber` was a particularly interesting and tricky case, since its side effects had to be atomic with respect to different processes. Nick wrote an [article](https://monadical.com/posts/Designing-A-Banking-System.html) about what we learned there, and later did a [talk at PyGotham](https://github.com/pirate/django-concurrency-talk) that’s worth checking out.
```python
# simplified excerpt from file controllers.py
class GameController:
# ...
def internal_dispatch(self, events: EventList) -> None:
for subj, event, kwargs in events:
event_func = getattr(subj, event)
event_func(**kwargs)
for sub in self.subscribers:
sub.dispatch(subj, event, **kwargs)
```
* Finally, `commit()` wraps up all the changes in Django’s `transaction.atomic()`, to make sure that either all of the changes to the game are made, or none are. Under the hood, that’s wrapping up all of our changes into an atomic (set of) SQL command(s) to commit our event history and in-memory model changes to permanent storage:
```python
# simplified excerpt from file controllers.py
class GameController:
# ...
def commit(self, should_broadcast=True) -> None:
with transaction.atomic():
for model in self.models:
model.save()
for sub in self.subscribers:
sub.commit()
if should_broadcast:
self.broadcast_to_sockets()
```
And there we go! Now we have both a current state of the world, defined in the database, and a history of how we got there.
This allows us to do some wonderful things in debugging and in testing. For example, any time a user reports an error, we just need the point in the history where it happened. Then we can create a test case that reproduces the error exactly. This stood out more than anywhere else in our “simulation tests,” where we play out games with random actions, and test a ton of invariants. Any time something looks wrong, the test dumps the hand history to a file, and a test case can be automatically created, ready to be fixed!
```python
# simplified excerpt from file test_simulation.py
class BotTest(SixPlayersTest):
def simulate_hand_and_test_assumptions(self, controller, stupid_ai):
curr_hand = controller.accessor.table.hand_number
while acc.table.hand_number == curr_hand:
action, kwargs = get_robot_move()
controller.dispatch(action, **kwargs)
try:
self.assert_consistent_pot_size(controller)
self.assert_animation_invariants(controller)
# ...many more
except Exception as error:
self.controller.log.save_to_file(
'test.json', notes=str(error)
)
raise type(error)(msg).with_traceback(err.__traceback__)
```
With the error log, we could pass it into a Replayer, and step through the error with `ipdb`.
#### Lessons Learned
Phew! Now that we’ve had a peek into what the architecture looked like, let’s look at the pros and cons of having chosen to build our platform with an event-driven architecture.
* **Major positive**: simulation/fuzz testing saved us an enormous amount of time long-term. Once we’d gotten to the point where we could reliably simulate millions of hands of poker without seeing errors, we didn’t see many problems in production either.
* **Positive**: our replayer made debugging a lot easier, but I’d say that, in practice, the replayer itself had bugs in it, which meant that it wasn’t quite as incredible a tool as it could have been. It did, however, encourage us to design our code in a way that made it easy to introspect, as we spent a lot of time in `ipdb`, viewing event logs and calling the `describe()` function that we habitually defined on any object of significant complexity.
* **Negative**: we chose a level of abstraction that was a bit too low at first, and changing the event model is nothing to sneeze at. On top of the usual headaches that come with refactoring core models in a codebase, changing an event also invalidates all previous historical logs that used that event! So instead of ruining all logs, we built an `Action -> Event` hierarchy, and then replayed the `Actions` in a history to produce an updated `Event`-level history when those had to be changed[^history]. We managed not to have to change the `Actions` almost ever, because by the time we designed them we understood our problem space better, and the Actions themselves were almost directly the vocabulary of a poker game (e.g. `raise`, `call`, `fold`…).
[^history]: While it would have been nice (and potentially safer) to keep past histories the same, we never came up with a good way to do it. We considered tagging all `Actions`/`Events` with a hash representing the version of the codebase in which they were produced, so that we could go back and replay them in their original form, but in practice we wanted to be able to pull up historical states and iterate through them without migrating the codebase on the fly. And do we really want to keep old versions of a codebase working, and runnable? So we scrapped the idea of backwards compatibility and just modified the entire history any time we changed the `Event` or `Action` models. As you might imagine, we tried our hardest to avoid this and it only happened once (or twice if you include the addition of `Actions` in the first place).
Overall, I feel confident that the positives outweigh the negatives, though I do wish we had taken the time to rewrite the game engine early on, when we realized that we should have used a slightly higher-level set of `Events`.
That’s all for the backend. Next time I’ll talk about the frontend, where we realized that animations, which need to quickly transform state over time, threw a new curveball into the design--one that eventually led us to building a [custom animations library](https://github.com/Monadical-SAS/redux-time)!
<br/>
<center>
<img src="https://monadical.com/static/logo-black.png" style="height: 80px" alt="Monadical logo"/><br/>
Monadical.com | Full-Stack Consultancy
*We build software that outlasts us*
</center>