# Demystifying Databases: Cracking the Code of Efficient Data Storage
*Written by Jose Benitez. Originally published 2023-05-30 on the [Monadical blog](https://monadical.com/blog.html).*
Picture this: You're in the early stages of a project, brimming with excitement as you bring your innovative web application to life. The possibilities seem endless, and you're ready to conquer the digital realm. But hold on! There's one critical aspect you can't afford to overlook: [choosing the right database](https://www.youtube.com/watch?v=W2Z7fbCLSTw).
Selecting the perfect database might sound like a mundane task, but let me assure you, it's anything but. As an experienced developer, I've witnessed the consequences of hasty decisions and ill-fitting databases. The repercussions can range from frustrating performance issues to the nightmare of data migration, [haunting you like an unrelenting spectre](https://icedq.com/data-migration/the-data-migration-process-and-the-potential-risks).
<center>
<img src="https://docs.monadical.com/uploads/65d39a3b-60f4-4198-a004-ea347a3c8095.jpg" width="400" style="border-radius: 8px; box-shadow: 6px 6px 6px rgba(0,0,0,0.2)" />
</center>
*Check out more info on [schema migration](https://en.wikipedia.org/wiki/Schema_migration) and [database migration](https://www.simform.com/blog/database-migration/).*
But fear not! In this article, I'm here to guide you through the database labyrinth, sharing my firsthand experience and insights to help you make informed decisions. We'll explore various database types, their inner workings, and the applications they integrate with. I'll also reveal the challenges I've faced and the workarounds I've discovered along the way. From the ever-reliable relational databases to cutting-edge blockchain technology, we'll cover it all. So, fasten your seatbelts, as we embark on a journey to demystify the world of databases and empower you to make the right choices for your projects.
Let’s get started!
## Relational Databases
<center>
<img src="https://docs.monadical.com/uploads/ac3ded75-b143-48a5-bd83-acfec42addf1.png" style="border-radius: 8px; box-shadow: 6px 6px 6px rgba(0,0,0,0.2)" />
</center>
<br/>
Let's kick off our database exploration with the tried and true [**relational databases**](https://aws.amazon.com/relational-database/). These databases have stood the test of time, making them one of the [first attempts](https://www.thinkautomation.com/histories/the-history-of-databases/) to structure and store data on computers. In fact, they continue to reign supreme as the [most widely used technique](https://www.c-sharpcorner.com/article/what-is-the-most-popular-database-in-the-world/) to store data in today's digital landscape.
Relational databases are the backbone of structured data management, offering a robust and efficient way to store and retrieve data. They utilize tables, schemas, and relationships to establish logical connections between data entities, ensuring data integrity and enabling powerful querying capabilities for advanced web development projects.
As illustrated in the image below, relational databases establish predefined relationships between data items, enabling smooth entity linking. By enforcing strict information constraints within each table, they ensure data [consistency](https://en.wikipedia.org/wiki/Consistency_(database_systems)) — a vital aspect of maintaining data integrity.
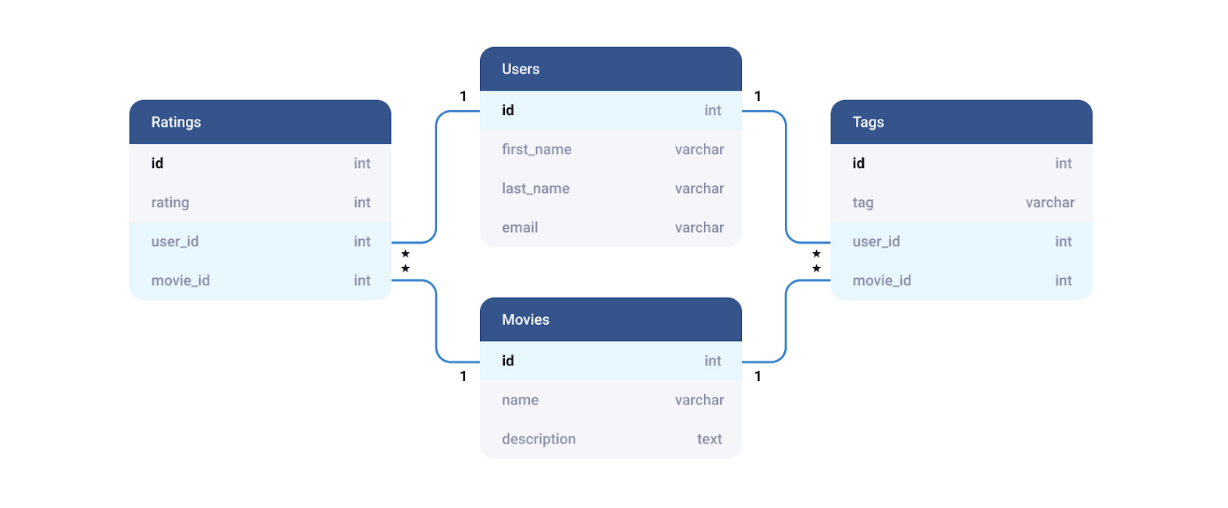
*Taken from [XBSoftware](https://xbsoftware.com/blog/main-types-of-database-management-systems/)*
Relational databases store data in separate tables, with the programmer responsible for defining these tables and distributing a single object across multiple entities. While almost every type of application can benefit from a relational database, it's important to acknowledge the [maintenance, scalability, and complexity limitations](https://databasetown.com/relational-database-benefits-and-limitations/) that come with this approach.
In my experience, I've employed relational databases in a range of applications, including customer relationship management software like Salesforce, an [online poker platform](https://oddslingers.com/), a dynamic real estate platform, and even a cutting-edge medical data synchronization app.
In each of these cases, my primary concern revolved around query optimization. While the relational database performed admirably overall, sometimes there remained complex computations which necessitated [complex queries](https://www.sqlshack.com/learn-sql-how-to-write-a-complex-select-query/); these queries, in turn, had the potential to slow down an application’s performance. While the impact on performance isn’t an inherent characteristic of relational databases, a developer could nonetheless encounter the problem on occasion and as a result should be aware of workarounds.
Using the example of the online poker game application, let me illustrate this challenge and how I came up with a solution. On the leaderboard page, I encountered the task of querying multiple tables to calculate the [hands](https://en.wikipedia.org/wiki/List_of_poker_hands) and games played by each player, ultimately ranking them based on their weekly and seasonal winnings. This process, although essential, proved to be a bottleneck, causing significant delays as the database engine scoured through the data, organized the information, and returned the results to the web page. Additionally, the database was queried on every page load—an unfavourable situation for a web page that demands lightning-fast load times in milliseconds.
To overcome this hurdle, I devised a solution: since the leaderboard data changed weekly, there was no need to query the database and compute the information on every page load. Instead, it made sense to implement a programmed task and store the information in an intermediary memory called a [cache](https://aws.amazon.com/caching/). As a result, anyone could request the leaderboard page view and access the cached data without unnecessarily taxing the database. Utilizing a caching mechanism significantly improved the application's performance and ensured a smooth user experience.
<center>
<img src="https://docs.monadical.com/uploads/62333c73-9369-4984-9d7a-ba7ef16ec918.png" style="border-radius: 8px; box-shadow: 6px 6px 6px rgba(0,0,0,0.2)" />
</center>
*If you're interested in exploring the code behind this leaderboard optimization, you'll find the complete open-source implementation in the [leaderboard file](https://github.com/Monadical-SAS/oddslingers.poker/blob/main/core/ui/views/leaderboard.py).*
Relational databases have undoubtedly shaped the foundations of modern data storage, but as we delve deeper into other database types, you'll discover alternative solutions that tackle the occasional limitations they pose.
## Document Databases
While relational databases rely on multiple tables to house interconnected data fragments, providing strong data integrity but potentially leading to a more rigid data model, [**document databases**](https://aws.amazon.com/nosql/document/) store comprehensive documents for each entity, allowing for flexibility in handling complex data structures. Document databases are like flexible storage containers for your data in any app that can benefit from it. Instead of using rigid tables and fixed schemas, you can store information in a document-oriented format, such as [JSON or BSON](https://www.mongodb.com/json-and-bson), allowing for easy adaptation and retrieval of complex, evolving data structures. Unlike their structured counterparts, document databases store all the information pertaining to a specific object within a single document in the database. The intriguing part? Each stored object can [differ from the others](https://en.wikipedia.org/wiki/Document-oriented_database) in structure and content, offering additional flexibility and adaptability.
Traditional relational databases (left) rely on multiple tables to house separate fragments of interconnected data. This approach stands in stark contrast to document databases (right), where every user is represented by a comprehensive document, encapsulating all their pertinent information.
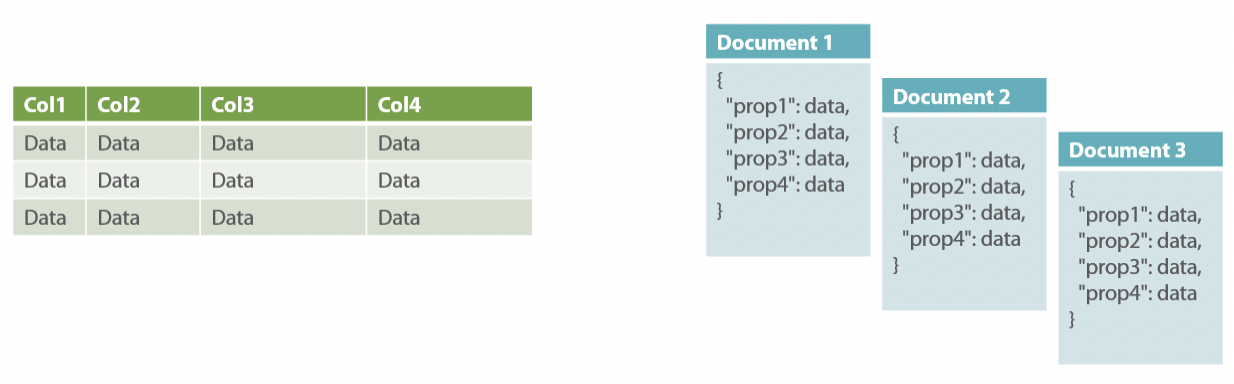
*Taken from [relational databases vs. NoSQL document databases](https://lennilobel.wordpress.com/2015/06/01/relational-databases-vs-nosql-document-databases/). This is a comparison between data stored in tables and data stored in documents.*
Over the years, I’ve used document databases in a variety of applications. From building a dynamic music streaming platform to developing an application rooted in the principles of the [Lean Startup methodology](https://theleanstartup.com/principles) and even constructing a robust restaurant point-of-sale system, document databases have been instrumental in handling unstructured data in both my personal and professional projects. Furthermore, I've utilized them as auxiliary databases for innovative functionalities like [staking](https://twitter.com/cyber_pharmacy/status/1547040501206945793) and [swapping](https://twitter.com/cyber_pharmacy/status/1487655698506784771) on [NFT platforms](https://www.blockchain-council.org/nft/nft-marketplace/).
However, their schema-less nature introduces its own set of challenges; for example, document databases sometimes [struggle](https://www.geeksforgeeks.org/document-databases-in-nosql/) with querying vast amounts of data, organizing complex sets of information, and performing comprehensive consistency checks.
Let's zoom in on my experience with the [Lean Startup methodology](https://www.universitylabpartners.org/blog/what-is-lean-startup-methodology) application and the obstacles I encountered, along with my solution. This application relies heavily on forms, which could have been implemented using traditional relational databases. But since forms vary and are not well-defined, I found that document databases were the superior choice in this case, as each time a user fills out a new form, a new document is created within the database. The image below provides a glimpse into a segment of the Lean Startup methodology's content stored within a document:
<center>
<img src="https://docs.monadical.com/uploads/e54ae806-969d-4558-ba57-2ffe89a9d49a.png" style="border-radius: 8px; box-shadow: 6px 6px 6px rgba(0,0,0,0.2)" />
</center>
*Note that in the document database, a collection comprises a set of documents.*
Should any field require an update, the database can conveniently populate the corresponding form with the document's content. Accessing specific document content is a breeze using designated paths like `/mainForms/TDNB3hGG152zmU6I1w2M`.
However, filtering documents poses a performance challenge, as the database engine must query each document that matches the specified criteria. Matters worsened when I searched across different collections, which amplified the computational burden. To mitigate these limitations, I took a crucial design process that involved organizing the information effectively into collections and documents, which ensured optimal resource utilization.
By employing intelligent collection and document structuring, it is possible to avoid the pitfalls associated with document databases, enabling efficient data retrieval and manipulation. These considerations play an important role in maximizing computing resources.
## Time-Series Databases
Think about the intricate record-keeping required by banks to capture each financial transaction passing through an account. Such transaction histories resemble append-only logs, intricately linked to timestamps. Tables or documents fail to meet the demands of this data structure, as they lack the optimization needed to handle the massive influx of writes and queries centred around time-based data ranges. Enter [**time-series databases**](https://hazelcast.com/glossary/time-series-database/), which provide a robust solution for managing and analyzing this unique data paradigm.
Time series databases are built specifically for handling massive amounts of time-stamped incoming data. They offer optimized storage, retrieval, and analysis features, making it a breeze to handle dynamic data that evolves over time; these characteristics make them perfect for managing metrics, IoT sensor readings, financial data, and more.
However, they diverge from [conventional databases](https://www.influxdata.com/blog/relational-databases-vs-time-series-databases/) in their limited support for data deletion and editing. Altering values within a time-series database introduces complexities and performance challenges, making them better suited for capturing immutable data streams.
To gain a visual understanding of time-series data, take a look at the snapshot below:
<center>
<img src="https://docs.monadical.com/uploads/b4f8e5d8-04f2-451b-a22e-8ee90855af51.png" style="border-radius: 8px; box-shadow: 6px 6px 6px rgba(0,0,0,0.2)" />
</center>
*Courtesy of Grafana’s monitoring stack for time-series databases.*
I've had the opportunity to leverage time-series databases in a unique application: monitoring my greenhouse variables. The first step involved setting up an array of sensors, measuring crucial factors such as pH, electrical conductivity, water level, and pump activation. Next, I connected these sensors to a microcontroller equipped with internet connectivity. Leveraging the [database's API](https://docs.influxdata.com/influxdb/v2.4/api-guide/api_intro/), I then pushed the sensor data into the database, meticulously tagging and organizing it within a designated bucket.
To extract valuable insights from this wealth of data, I utilized [Flux](https://docs.influxdata.com/flux/v0.x/get-started/syntax-basics/), a query language tailored for time-series data manipulation. Flux processed the data before presenting it through a user-friendly interface, enabling me to assemble customized monitoring views with ease. Allow me to share a glimpse of my greenhouse pH control interface, showcasing four distinct signals: the desired pH, the current pH, and the yellow and green points representing dosages of acid or alkaline solutions employed to adjust the pH level of the water tank.
<center>
<img src="https://docs.monadical.com/uploads/c5c08a59-d7de-481b-b087-b62794ccb9a0.png" style="border-radius: 8px; box-shadow: 6px 6px 6px rgba(0,0,0,0.2)" />
</center>
<br/>
While this view represents a rudimentary example, the flexibility of time-series databases allows for the creation of complex monitoring panels catering to diverse industries such as finance and industrial applications that hinge on temporal data.
## Graph Databases
[**Graph databases**](https://neo4j.com/developer/graph-database/) store data as interconnected nodes and relationships, providing advanced features for complex data querying and exploration. By utilizing nodes, edges, and properties, graph databases create a network of connections that can be easily traversed. In this realm, relationships are highly valued and persistently stored in the database, allowing for speedy retrieval of intricate data connections.
<center>
<img src="https://docs.monadical.com/uploads/abe2cb80-3cd9-4d29-b459-745061e02b13.png" style="border-radius: 8px; box-shadow: 6px 6px 6px rgba(0,0,0,0.2)" />
</center>
*While relational databases handle data relationships, graph databases excel at linking massive and complex entities.*
One intriguing project where I used graph databases was with [Currents](https://a.currents.fm/), an innovative music platform that acted as a bridge, connecting music enthusiasts with music curators through a federated royalty distribution system. Artists carved their unique channels, where they could share their musical creations, while fans eagerly subscribed to these channels. Fans also had the opportunity to subscribe to curated lists, consequently contributing to the financial support of the artists featured on these lists. To foster a sense of solidarity within the artistic community, artists themselves could endorse and uplift fellow creators, referred to as beneficiaries.
However, as the relationships within this musical ecosystem grew increasingly intricate, the computation of royalties spiralled into a daunting task, so I turned to graph databases. By strategically storing and organizing the necessary information within the graph database, I was able to transform royalty computation and tracking into a remarkably manageable endeavour. The graph database deftly handled the efficient management of the complex web of relationships.
To provide you with a visual glimpse into this musical graph database, notice the image below. Here, graph databases map artists, channels, and fans as ‘entities’ and subscriptions and beneficiaries as *'relationships’*:
<center>
<img src="https://docs.monadical.com/uploads/e72b3543-1e92-4d5a-a285-34eb76ab7948.png" style="border-radius: 8px; box-shadow: 6px 6px 6px rgba(0,0,0,0.2)" />
</center>
*A graph database drawing of a music streaming platform project. The red dots represent payment methods, green are users, and pink are artist channels.*
The innate visual nature of graph databases makes them an ideal choice for managing highly interconnected data landscapes. In my case, their ability to track and compute royalty payments demonstrates their capacity of handling complex relationships, solidifying their indispensable role in projects of this nature.
## Key-Value Databases
[**Key-value databases**](https://redis.com/nosql/key-value-databases/), a type of NoSQL database, are like the versatile Swiss army knives of data storage. They offer a simple yet powerful approach where data is stored as key-value pairs, providing a flexible and efficient way to retrieve and store information. These features make them perfect for a wide range of use cases such as caching/queuing, session management, and handling distributed systems with finesse.
The images below provide a glimpse into this dynamic exchange, showcasing how messages flow from producer to consumers. Two distinct mapping strategies come into play, each with its own charm, as the choice of mapping depends entirely on the unique demands of the application at hand.
In the first strategy, processes produce many messages. Then, other processes consume those messages in an asynchronous and random way. This is useful for applications that share resources among many consumers, such as IO buffers, pipes, CPUs, or network adapters.
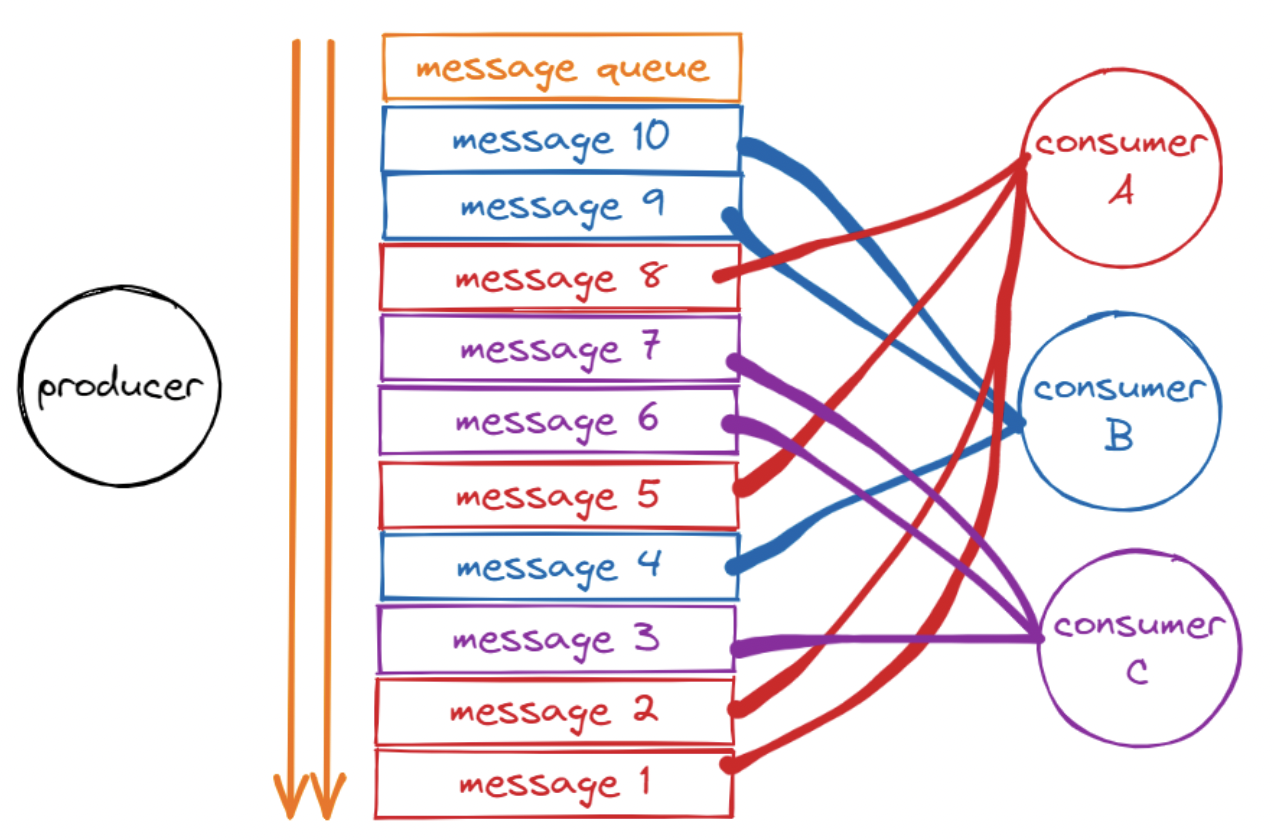
*Taken from [The Perfect Message Queue Solution Based on the Redis Stream Type](https://betterprogramming.pub/the-perfect-message-queue-solution-based-on-the-redis-stream-type-ccf273554178)*
A second mapping strategy outlines another possibility of mapping messages from producers to consumers, following rules like:
- Pass Message 1 to Consumer 1, Message 2 to Consumer 2, etc.
- Pass Message 1 to every consumer, then Message 2 to every consumer, etc.
Those two kinds of mapping look like this:
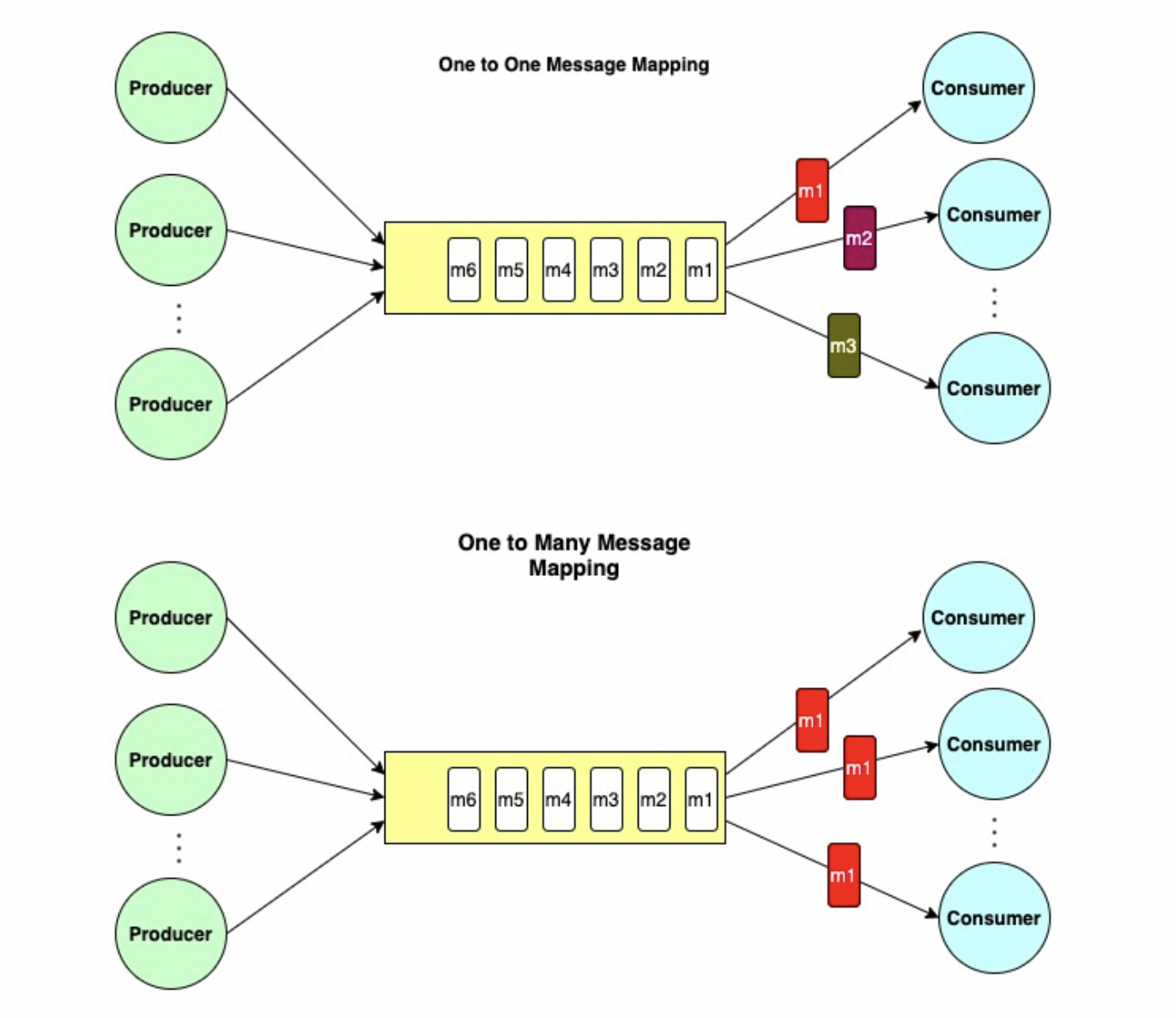
*Taken from [Rqueue](https://github.com/sonus21/rqueue). Queues are represented in yellow boxes.*
In both cases, messages can be mapped from any producer to any consumer depending on the application’s needs. Messages can also contain information about their target consumer.
Let's look at a situation in which I used queues with the key-value approach to enhance the execution of a set of tasks. I had set out to develop a program that would collect data from an array of sensors gracefully adorning a vehicle. The task at hand involved transmitting these readings to a remote server, thus paving the way for a wealth of insights. However, hurdles awaited me. The sensors, with their intrinsic nature, operated at their own pace, introducing delays in delivering the readings. The server, too, exhibited a sluggish response time, hindering the program's execution. To add to the complexity, the execution time of the program's tasks varied significantly, further worsening the program's clumsiness and roughness.
This clumsy awkwardness meant that I had to find a workaround. I realized that in this particular application, the readings from the sensors could play the role of producers, while pushing the readings to a server could act as the consumer program. With both programs working asynchronously, readings and pushes worked smoothly by not interfering with each other’s executions. However, the main challenge lay in facilitating seamless data sharing between the two programs. In this case, queues emerged as the ultimate saviour, providing a conduit to store and retrieve the readings. With this newfound solution, I divided the program into discrete tasks, relying on the key-value database used as a queue to foster data exchange between these tasks.
## Blockchains
[**Blockchains**](https://aws.amazon.com/what-is/blockchain/) are the heralds of a new era for databases. These distributed, cryptographically secured systems hold the key to revolutionizing information storage, offering a wealth of intriguing possibilities. With their decentralized nature, blockchains not only [safeguard user privacy](https://en.wikipedia.org/wiki/Privacy_and_blockchain) by [protecting personal information](https://www.bitstamp.net/learn/security/how-private-is-blockchain/), but also introduce a [new way of owning data](https://lorisleiva.com/owning-digital-assets-in-solana/a-new-way-of-owning-data), thereby transforming the way we perceive and interact with digital assets.
At their core, blockchains are decentralized digital ledgers that ensure secure and transparent record-keeping without relying on intermediaries. They use clever cryptographic techniques to create a chain of blocks, making transactions or information tamper-resistant and trustworthy. Transactional authenticity is achieved through the use of [digitally signed transactions](https://en.wikipedia.org/wiki/Digital_signature), with fees playing a pivotal role in [supporting the network's economy](https://docs.solana.com/transaction_fees).
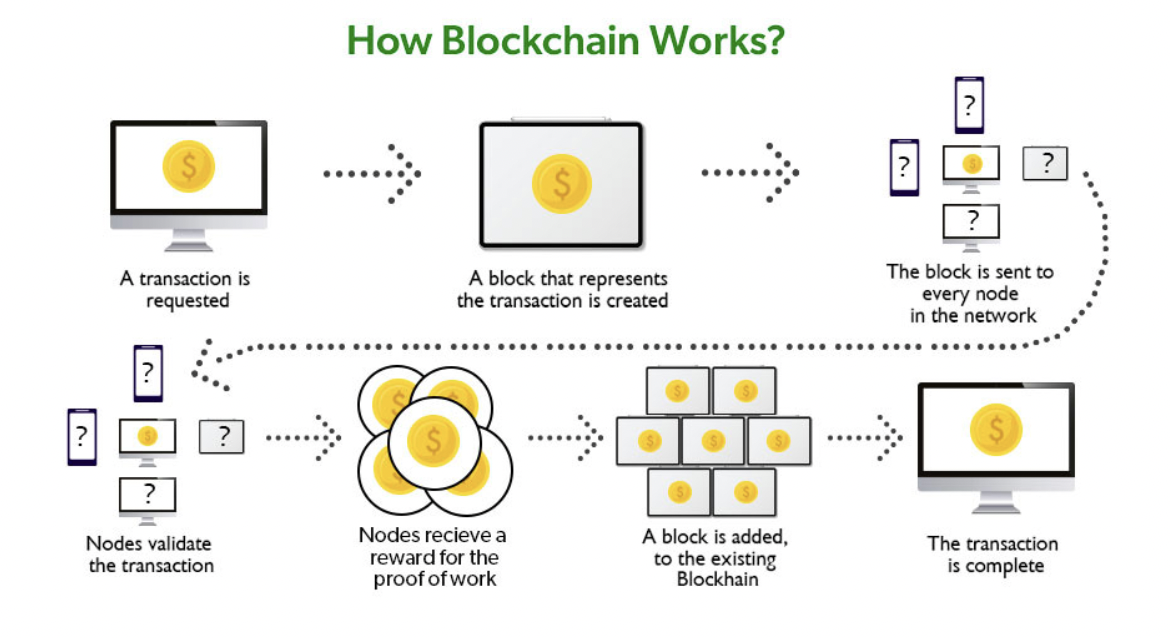
*Taken from [Geeks for Geeks](https://www.geeksforgeeks.org/how-does-the-blockchain-work/)*
In the modern landscape, blockchains have transcended their humble origins, evolving into dynamic platforms that are capable of [executing programs](https://solanacookbook.com/core-concepts/programs.html#deploying-programs) with [increasing sophistication and power](https://medium.com/coinmonks/the-blockchain-running-applications-80ec0d9c3eb0). This newfound versatility has fueled their adoption across diverse domains, ranging from financial applications to goods traceability, digital identity management, gaming, voting systems, digital certificates, healthcare, [and beyond](https://www.simplilearn.com/tutorials/blockchain-tutorial/why-is-blockchain-important).
One unique facet of blockchains is their association with [Non-Fungible Tokens (NFTs)](https://en.wikipedia.org/wiki/Non-fungible_token), which have garnered considerable attention and sparked somewhat of a renaissance in the digital art realm. Within the blockchain ecosystem, a record is referred to as an "account", capable of housing data or acting as an executable program. In the context of NFTs, accounts serve as repositories for unique tokens, each representing a distinctive digital asset.
Personally, I had the opportunity to immerse myself in the world of NFTs and engage with their vibrant communities. The goal of the platform I worked on was to burn NFTs from one collection to produce another NFT from a new collection.
The journey began with the creation of a web interface, allowing users to initiate the burning process by submitting a transaction to the blockchain. To ensure a smooth experience, I developed a program that diligently tracked the transaction's status. Upon successful completion, the program orchestrated the transfer transaction, enabling users to obtain their new NFTs.
Yet, as with any venture, challenges did emerge. The burn transaction, susceptible to network instability, occasionally faltered or timed out, disrupting the delicate flow of operations. Moreover, transaction confirmations suffered from unpredictable delays, which introduced inconsistencies and jeopardized the program's ability to track the burned NFTs. This had the potential of leaving users without their new NFTs, an unacceptable outcome.
The key to solving this issue lay in abandoning the reliance on a separate program, instead consolidating the entire exchange process into a single transaction. Initially, the complexity of requiring two signatures, one for burning and another for transferring the NFT, had led me to opt for separate transactions. However, through a process of trial and error, I discovered that merging the two steps into a single serialized transaction, accompanied by the appropriate signatures, aligned smoothly with the inherent nature of blockchain transactions. This newfound approach ensured the integrity and continuity of the exchange process.
## Final Thoughts
As you venture into the realm of databases, I encourage you to consider the [multitude of effective methods available](https://dev.to/gduple/database-types-explained-4ja7) for storing information on computers. Just as you can organize your personal belongings in various ways, ranging from a cluttered junk drawer in your kitchen to meticulously labelled files, the world of databases offers a vast array of solutions to suit your specific needs and requirements.
To further expand your knowledge and discover additional guidance on selecting the correct database for specific applications, I recommend [exploring the resources](https://scientificprogrammer.net/2019/08/18/when-nosql-is-better-choice-than-rdbms-and-when-its-not/) provided in this link and the additional links below. These valuable references offer further insights and perspectives from experts in the field, enhancing your understanding and refining your decision-making process. And if you’re an academic and want to go deeper into the theory, be sure to check out [database foundations](http://webdam.inria.fr/Alice/).
Lastly, don’t overlook the fundamental concepts of [atomicity, consistency, isolation, and durability (ACID)](https://en.wikipedia.org/wiki/ACID), as they play a vital role in ensuring data integrity. These principles form the bedrock of reliable and robust databases, safeguarding the integrity and reliability of your valuable information.
I hope that the insights and solutions shared here will serve as valuable tools as you embark on your own database journey. Experimentation and exploration are the keys to unlocking the full potential of these powerful tools. Allow the experiences and lessons learned to shape your path, enabling you to build efficient and robust systems that unleash the true power of data. Finally, embrace curiosity, adaptability, and continuous learning as you navigate the ever-changing landscape. By doing so, you will be poised to conquer new challenges, innovate with confidence, and harness the transformative potential of data in the pursuit of progress.
<center>
<img src="https://docs.monadical.com/uploads/f946b338-3167-46d0-99ff-7ef717b40190.png" style="border-radius: 8px; box-shadow: 6px 6px 6px rgba(0,0,0,0.2)" />
</center>
<br/>
Some database engines for each paradigm, in no particular order:
**Relational:** [MySQL](https://www.mysql.com/), [PostgresQL](https://www.postgresql.org/), [MariaDB](https://mariadb.org/)
**Document:** [MongoDB](https://www.mongodb.com/), [Firestore](https://firebase.google.com/docs/firestore)
**Time-Series:** [InfluxDB](https://www.influxdata.com/), [Timestream](https://aws.amazon.com/timestream/)
**Graphs:** [Neo4j](https://neo4j.com/), [ArangoDB](https://www.arangodb.com/), [Memgraph](https://memgraph.com/), [ApacheAGE](https://age.apache.org/)
**Key-Value:** [Redis](https://redis.io/), [DynamoDB](https://aws.amazon.com/dynamodb/), [RabbitMQ](https://www.rabbitmq.com/)
**Blockchain:** [Ethereum](https://ethereum.org/en/), [Solana](https://solana.com/)

Jose Benitez
is a Web developer of Monadical
